

2021Web前端中高级面试题复盘
发布于2021-03-07 21:38 阅读(661) 评论(0) 点赞(8) 收藏(3)
一、HTML基础
1.常见浏览器的内核
(1)IE: trident 内核
(2)Firefox:gecko 内核
(3)Safari: webkit 内核
(4)Opera: 以前是 presto 内核,Opera 现已改用 Google Chrome 的 Blink 内核
(5)Chrome:Blink(基于 webkit,Google 与 Opera Software 共同开发 )
2.HTML 开头Doctype的作用
html网页声明,位于文档中的最前面的位置,处于标签之前。此标签可告知浏览器文档使用
哪种 HTML 或 XHTML 规范。(重点:告诉浏览器按照何种规范解析页面)
3.HTML5新特性
-
用于绘画canvas 元素。
-
用于媒介回放du的 video 和 audio 元素。
-
地理位置:Geolocation API访问地理位置,即通过window.navigator.geolocation来实现访问
-
本地离线存储localStorage 长期存储数据,浏览器关闭后数据不丢失;sessionStorage 的数据在浏览器关闭后自动删除。
-
语意化更好的内容元素,比如 article、footer、header、nav、section。
-
表单控件,calendar、date、time、email、url、search。
4.对 WEB 标准以及 W3C 的理解与认识?
标签闭合、标签小写、不乱嵌套、提高搜索机器人搜索几率、使用外链 css 和js 脚本、结构行为表现的分离、文件下载与页面速度更快、内容能被更多的用户所访问、内容能被更广泛的设备所访问、更少的代码和组件,容易维护、改版方便,不需要变动页面内容、提供打印版本而不需要复制内容、提高网站易用性。
5.HTML5 行内元素有哪些,块级元素有哪些, 空元素有哪些?
(1)行内元素
- a - 锚点
- img - 图片
- input - 输入框
- select - 项目选择
- span - 常用内联容器,定义文本内区块
(2)块元素
- div - 常用块级容易,也是 css layout 的主要标签
- form - 交互表单
- h1~h5 -标题
- table - 表格
- ul - 非排序列表
(3)空元素( 在 HTML[1] 元素中,没有内容的 HTML 元素被称为空元素 )
- br 换行
- hr 分隔线
- input 文本框等
- img 图片
- link | meta 引入资源标签
6.什么是 WebGL,它有什么优点?
WebGL(全写 Web Graphics Library )是一种 3D 绘图标准,这种绘图技术标准允许把 JavaScript 和 OpenGL ES 2.0 结合在一起,通过增加 OpenGL ES 2.0 的一个 JavaScript 绑定,WebGL 可以为 HTML5 Canvas 提供硬件 3D 加速渲染,这样 Web 开发人员就可以借助系统显卡来在浏览器里更流畅地展示 3D 场景和模型了,还能创建复杂的导航和数据视觉化。显然,WebGL 技术标准免去了开发网页专用渲染插件的麻烦,可被用于创建具有复杂 3D 结构的网站页面,甚至可以用来设计 3D 网页游戏等等。
WebGL 完美地解决了现有的 Web 交互式三维动画的两个问题:
-
第一,它通过 HTML 脚本本身实现 Web 交互式三维动画的制作,无需任何浏览器 插件支持 ;
-
第二,它利用底层的图形硬件加速功能进行的图形渲染,是通过统一的、标准的、跨平台的 OpenGL 接口实现的。
通俗说 WebGL 是c基于anvas 绘图中的 3D 版本。因为原生的 WebGL 很复杂,我们经常会使用一些三方的库,如 three.js 、echarts等,这些库多数用于 HTML5 游戏开发。
7.cookies,sessionStorage 和localStorage 的区别?
1)Cookie
- 每个域名存储量比较小(各浏览器不同,大致 4K )
- 所有域名的存储量有限制(各浏览器不同,大致 4K )
- 有个数限制(各浏览器不同)
- 会随请求发送到服务器
2)LocalStorage
- 永久存储
- 单个域名存储量比较大(推荐 5MB ,各浏览器不同)
- 总体数量无限制
3)SessionStorage
- 只在 Session 内有效
- 存储量更大(推荐没有限制,但是实际上各浏览器也不同)
8.说说你对 HTML 语义化的理解?
(1)什么是 HTML 语义化?
<基本上都是围绕着几个主要的标签,像标题( H1~H6 )、列表( li )、强调( strong em )等等 >
根据内容的结构化(内容语义化),选择合适的标签(代码语义化)便于开发者阅读和写出更优雅的代码的同时让浏览器的爬虫和机器很好地解析。
(2)为什么要语义化?
- 为了在没有 CSS 的情况下,页面也能呈现出很好地内容结构、代码结构 : 为了裸奔时好看;
- 用户体验:例如 title、 alt用于解释名词或解释图片信息、 label 标签的活用;
- 有利于SEO:和搜索引擎建立良好沟通,有助于爬虫抓取更多的有效信息:爬虫依赖于标签来确定上下文和各个关键字的权重;
- 方便其他设备解析(如屏幕阅读器、盲人阅读器、移动设备)以意义的方式来渲染网页;
- 便于团队开发和维护,语义化更具可读性,是下一步网页的重要动向,遵循 W3C标准的团队都遵循这个标准,可以减少差异化。
(3) 语义化标签
header、footer、nav、section、article、aslde、figure(媒体元素,比如一些视频,图片啊等等)
9.link 和@import 的区别?
- 区别 1: link 是 XHTML 标签,除了加载 CSS 外,还可以定义 RSS 等其他事 务; @import 属于 CSS范畴,只能加载 CSS 。
- 区别 2: link 引用 CSS 时,在页面载入时同时加载; @import 需要页面网页完全载入以后加载。
- 区别 3: link 是 XHTML 标签,无兼容问题; @import 是在 CSS2.1 提出的,低版本的浏览器不支持。
- 区别 4: link 支持使用 Javascript 控制 DOM 去改变样式;而 @import 不支 持。
二、CSS基础
1.CSS 的盒子模型
- 标准的盒模型:width = content
- IE 盒模型:width = content + padding + border + border
2.几种清除浮动的方法
- 父级 div 定义 height
- 结尾处加空 div 标签 clear:both
- 父级 div 定义 伪类:after 和zoom(兼容ie6、7)
#parent:after{
content:" ";
height:0;
visibility:hidden;
display:block;
clear:both;
}
- 父级 div 定义 overflow:hidden / overflow:auto
3.box-sizing 属性和用法
标准盒子模型:width +padding + border
怪异盒子模型(IE盒子模型):width + border
4.BFC (是什么,如何产生,作用)
BFC是什么
BFC(Block Formatting Context)即“块级格式化上下文”
可以把 BFC 想象成一个大箱子,箱子外边的元素将不与箱子内的元素 产生作用
如何产生 BFC
当一个 HTML 元素满足下面条件的任何一点,都可以产生 Block Formatting
Context:
a、float 的值不为 none
b、overflow 的值不为 visible
c、display 的值为 table-cell, table-caption, inline-block 中的任何一个
d、position 的值不为 relative 和 static
CSS3 触发 BFC 方式则可以简单描述为:在元素定位非 static,relative 的情况下触发,float 也是一种定位方式。
BFC 的作用与特点
作用:不和浮动元素重叠,清除外部浮动,阻止浮动元素覆盖
特点:
- float 的值不为 none。
- overflow 的值不为 visible。
- display 的值为 table-cell, table-caption, inline-block 中的任何一个。
- position 的值不为 relative 和 static。
5.页面布局的方式有哪些?
- 多栏——bootstrap栅格系统
- 弹性——FlexBox
- 瀑布流
- 响应式布局
- *流式
- *双飞翼
三、js基础
JS 数据类型
基本类型:Number、Boolean、String、null、undefined、symbol(ES6 新增的),BigInt(ES2020)
引用类型:Object,对象子类型(Array,Function)
bigint
带符号的范围是-9223372036854775808到9223372036854775807。无符号的范围是0到18446744073709551615。
int 普通大小的整数。带符号的范围是-2147483648到2147483647。无符号的范围是0到4294967295。就是值得范围的问题,如果需要大于int的范围,就用bigint.
事件流
事件流是网页元素接收事件的顺序,"DOM2级事件"规定的事件流包括三个阶段:事件捕获阶段、处于目标阶段、事件冒泡阶段。
首先发生的事件捕获,为截获事件提供机会。然后是实际的目标接受事件。最后一个阶段是时间冒泡阶段,可以在这个阶段对事件做出响应。
虽然捕获阶段在规范中规定不允许响应事件,但是实际上还是会执行,所以有两次机会获取到目标对象。
例如:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>事件冒泡</title>
</head>
<body>
<div>
<p id="parEle">我是父元素 <span id="sonEle">我是子元素</span></p>
</div>
</body>
</html>
<script type="text/javascript">
var sonEle = document.getElementById('sonEle');
var parEle = document.getElementById('parEle');
parEle.addEventListener('click', function () {
alert('父级 冒泡');
}, false);
parEle.addEventListener('click', function () {
alert('父级 捕获');
}, true);
sonEle.addEventListener('click', function () {
alert('子级冒泡');
}, false);
sonEle.addEventListener('click', function () {
alert('子级捕获');
}, true);
</script>
当容器元素及嵌套元素,即在捕获阶段又在冒泡阶段调用事件处理程序时:事件按DOM事件流的顺序执行事件处理程序:
父级捕获——>子级冒泡——>子级捕获——>父级冒泡
1.call、apply、bind三者的用法和区别
(1)三者的使用
func.call(thisArg, arg1, arg2, ...)
func.bind(thisArg, arg1, arg2, ...)
func.apply(thisArg, [arg1, arg2, ...])
(2)手写call()方法
Function.prototype.myCall = function(thisArg, ...args) {
thisArg.fn = this // this指向调用call的对象,即我们要改变this指向的函数
return thisArg.fn(...args) // 执行函数并return其执行结果
}
// 尝试第一个例子
function sum(num1, num2) {
return num1 + num2;
}
function callSum(num1, num2) {
return sum.myCall(this, num1, num2);
}
console.log(callSum(10, 10)); // 20
(3)手写apply()方法
Function.prototype.myApply = function(thisArg, args) {
thisArg.fn = this // this指向调用apply的对象,即我们要改变this指向的函数
return thisArg.fn(this, args) // 执行函数并return其执行结果
}
// 尝试第一个例子
function sum(num1, num2) {
return num1 + num2;
}
function callSum(num1, num2) {
return sum.myApply(this, [num1 + num2]);
}
console.log(callSum(10, 10)); // 20
(4)手写bind()方法:语法和call一模一样,区别在于立即执行还是等待执行,bind不兼容IE6~8
fn.call(obj, 1, 2); // 改变fn中的this,并且把fn立即执行 fn.bind(obj, 1, 2); //
改变fn中的this,fn并不执行
Function.prototype.myBind = function(...rest1) {
var self = this
var context = rest1.shift() // 取得第一个参数(即执行环境),并删除
return function(...rest2) {
return self.apply(context, [...rest1, ...rest2])
}
}
// 测试
window.color = 'red';
var o = { color: 'blue' };
function sayColor() {
console.log(this.color)
console.log(arguments)
}
var objectSayColor = sayColor.myBind(o, '1', '2');
objectSayColor('3'); // 输出 "blue" 和 "1", "2", "3" 相关的数据
区别
- 相同点:通过 apply 和 call 改变函数的 this 指向,他们两个函数的第一个参数都是一样的表示要改变指向的那个对象;
- 不同点:第二个参数,apply 是数组,而 call 则是参数列表(arg1,arg2…这种形式)。通过 bind 改变 this 作用域会返回一个新的函数,这个函数不会马上执行。
2.闭包
闭包是指有权访问另一个函数作用域中的变量的函数。创建闭包的常见方式:在一个函数内部创建另一个函数。
一般来讲,当函数执行完毕后,局部活动对象就会被销毁,内存中仅会保存全局作用域(全局执行环境的变量对象)。但闭包则有所不同。
一个闭包的例子:
function createFunction(width, height) {
return function(object) {
var area = object[width] * object[height]
return area
}
}
// 创建函数
var areaFunc = createFunction('width', 'height');
// 调用函数
var area = areaFunc({ width: 3, height: 2 }) //5
这里的 areaFunc 方法的作用域链中,包含了闭包的活动对象(arguments,object)、createFunction()的活动对象(arguments,width,height)和全局变量对象(createFunction,area)。当createFunction()的函数返回后,其执行环境的作用域链会被销毁,但它的活动对象仍然留在内存中,这时需要我们手动销毁匿名函数,以释放内存。
// 解除对匿名函数的引用(释放内存)
areaFunc = null;
注:由于闭包会携带包含它的函数的作用域,因此会比其他函数占用更多的内存。所以,我们最好在必要时才使用闭包。
3.Promise
(1)promise的三种状态:pending、fuulfiled/resolved、rejected;
(2)catch()
catch()方法返回一个Promise,并且处理拒绝的情况。
(3)finally()
不管promise最后的状态,在执行完then或catch指定的回调函数以后,都会执行finally方法指定的回调函数。
例如:
var promise = new Promise(function(resolve, reject) {
console.log("promise")
window.setTimeout(function(){
if (false){
resolve('huangbiao');
} else {
debugger
reject('error');
}
},1000)
}).then(function(){
console.log('success');
}).catch(function(){
console.log('catch');
}).finally(function(){
console.log('finally');
});
(4)resolve()
Promise.resolve()用于将现有对象转换为Promise对象,从而控制异步流程为。
而立即resolve的Promise对象是在本轮“事件循环”(Event loop)的结束时,而不是在下一轮“事件循环”的开始时。
例如:
setTimeout(function () {
console.log('three');
}, 0);
Promise.resolve().then(function () {
console.log('two');
});
console.log('one');
// one
// two
// three
(5)reject()
Promise.reject()方法返回一个带有拒绝原因的Promise对象。
(6)all()
Promise.all可以将多个Promise实例包装成一个新的Promise实例。同时,成功和失败的返回值是不同的,成功的时候返回的是一个结果数组,而失败的时候则返回最先被reject失败状态的值。
Promse.all在处理多个异步处理时非常有用,比如说一个页面上需要等两个或多个ajax的数据回来以后才正常显示,在此之前只显示loading图标。
//例如:
let p1 = new Promise((resolve, reject) => {
resolve('成功了')
})
let p2 = new Promise((resolve, reject) => {
resolve('success')
})
let p3 = Promse.reject('失败')
Promise.all([p1, p2]).then((result) => {
console.log(result) //['成功了', 'success']
}).catch((error) => {
console.log(error)
})
Promise.all([p1,p3,p2]).then((result) => {
console.log(result)
}).catch((error) => {
console.log(error) // 失败了,打出 '失败'
})
(7)race()
顾名思义,Promse.race就是赛跑的意思,意思就是说,Promise.race([p1, p2,
p3])里面哪个结果获得的快,就返回那个结果,不管结果本身是成功状态还是失败状态。
4.函数柯里化(curry)
函数柯里化,用于创建已经设置好了一个或多个参数的函数。
例如:
function add(num1, num2) {
return num1 + num2;
}
function curriedAdd(num2) {
return add(5, num2);
}
console.log(add(2, 3)); // 5
console.log(curriedAdd(3)); // 8
实现如下:
function curry(fn) {
var args = Array.prototype.slice.call(arguments, 1); // 删除传入的function,获取其余参数
return function() {
var innerArgs = Array.prototype.slice.call(arguments); // 取得参数
var finalArgs = args.concat(innerArgs);
return fn.apply(null, finalArgs); // 这里不需要考虑执行环境,所以null
}
}
// 测试
function add(num1, num2) {
return num1 + num2;
}
var curriedAdd = curry(add, 5);
console.log(curriedAdd(3)); // 8
// 也可以第一次就直接传递完参数
var curriedAdd2 = curry(add, 5, 3);
console.log(curriedAdd2()); // 8
5.防抖和节流的区别
防抖是延迟执行,而节流是间隔执行
比如,窗口的onresize事件,我们分别使用防抖和节流,时间设为500毫秒。
- 使用防抖:若你一直在改变窗口大小,则你的处理方法不会执行,只有你停止改变窗口大小后的500毫秒后,才会执行你的处理方法。
- 使用节流:若你一直在改变窗口大小,则每500毫秒就会执行一次你的处理方法。
(1)节流函数的实现
function throttle(func, wait) {
let timeout = null
return function() {
const context = this
const args = arguments
if (!timeout) {
timeout = setTimeout(() => {
timeout = null
func.apply(context, args)
}, wait)
}
}
}
function handleDom() {
console.log('盒子的位置:', dom.offset.x, dom.offset.y)
}
window.on('resize', function() {
throttle(handleDom, 500); //这里调用节流函数获取拖动期间每隔500毫秒盒子的位置
)
应用场景:监听页面鼠标滚动
(2)函数防抖的实现
function debounce (func, wait) {
let timeout = null
return function() {
const context = this
const args = arguments
if (timeout) clearTimeout(timeout)
timeout = setTimeout(() => {
func.apply(context, args)
}, wait)
}
}
function handelInput(e) {
const {value} = e.target
this.getSearchData(value)
}
debouce(handelInput(e), 500)
应用场景:搜索框搜索。
6.数组扁平化
(1)ES6中的flat()
const arr = [1, [1,2], [1,2,3]].flat()
(2)使用正则
const arr = [1, [1,2], [1,2,3]]
const str = `[${JSON.stringify(arr).replace(/(\[|\])/g, '')}]`
JSON.parse(str)
(3)使用reduce() (兼容到ie9)
var array = [1, [1, 2], [1, 2, 3]];
function flat(array) {
return arry.reduce((prev, cur)=> {
return prev.contact(cur instanceof Array ? flat(cur) : cur)
}, [])
}
//调用flat函数,实现数组的扁平化
flat(array)
注意: reduce() 对于空数组是不会执行回调函数的。所以在如上返回函数之后会自动加上一个空数组
7.深拷贝,浅拷贝
深浅拷贝都是针对引用类型而言的,浅拷贝只是复制对象的引用,如果拷贝后的对象发生变化,原对象也会发生变化。只有深拷贝才是真正地对对象的拷贝。
(1)浅拷贝
浅拷贝只是复制了引用,并没有实现真正的复制。
var arr = [1,2,3];
var cloneArr = arr;
cloneArr.push(4);
console.log(arr); // [1, 2, 3, 4]
console.log(cloneArr); // [1, 2, 3, 4]
(2)深拷贝
深拷贝是完完全全的拷贝,它们之间彼此隔离,互不影响。
实现深拷贝的方法主要有两种:
- 利用 JSON 对象中的 parse 和 stringify
- 利用递归来实现每一层都重新创建对象并赋值
(1)JSON 对象中的 parse 和 stringify
var arr = [1,2,3];
var cloneArr = JSON.parse(JSON.stringify(arr));
cloneArr.push(4);
console.log(arr); // [1, 2, 3]
console.log(cloneArr); // [1, 2, 3, 4]
这个方法确实实现了深拷贝,也是我们最常用的一种方法,但对于一些复杂的引用类型,就存在问题
var obj = {
name: 'Tom',
sayName: function(){
console.log(this.name)
}
}
var cloneObj = JSON.parse(JSON.stringify(obj));
console.log(obj); // {name: "Tom", sayName: ƒ}
console.log(cloneObj); // {name: "Tom"}
我们发现,它并没有将方法复制下来。原因是:undefined、function、symbol 会在转换过程中被忽略。。。
(2)递归实现
function deepClone(obj) {
if (typeof obj !== 'object') return; //如果不是对象,直接跳出
var newObj = obj instanceof Array ? [] : {}; // 判断复制的目标是数组还是对象
for (var i in obj) {
if (obj.hasOwnProperty(key)) {
newObj[i] = typeof obj[i] == 'object' ?
deepClone(obj[i]) : obj[i]; // 如果值是对象,就递归一下, 否则就直接赋值
}
}
return newObj;
}
// 测试
var obj = {
name: 'Tom',
sayName: function(){
console.log(this.name)
}
}
var cloneObj = deepClone(obj);
obj.sex = '女';
console.log(obj); // {name: "Tom", sayName: ƒ}
console.log(cloneObj); // {name: "Tom", sayName: ƒ}
JavaScript中的有的方法也能实现拷贝,比如:concat()和slice(),ES6中的Object.assgin()和…展开运算符。
- concat 只是对数组的第一层进行深拷贝
- slice 只是对数组的第一层进行深拷贝
四、前端基础知识
1.http 和 https的区别
(1) 申请方式不一致:https协议需要ca证书,且费用较高,http申请不需要证书和费用;
(2) 传输协议不一致:http是超文本传输协议,信息是明文传输,而http是具有安全性的SSL加密传输协议;
(3) 端口不一致:一般而言,http 协议的端口为 80,https的端口为 443;
(4) 安全性不一致:http 的连接很简单,是无状态的;HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全
2.tcp 三次握手
客户端和服务端都需要直到各自可收发,因此需要三次握手。
简化三次握手:

从图片可以得到三次握手可以简化为:
C 发起请求连接 S 确认,也发起连接 C 确认(C:客户端,S:服务器端)
每次握手的过程:
第一次握手:S 确认自己可以接受 C 发送的报文段;
第二次握手:C 确认 S 收到了自己发送的报文段,并且确认自己可以接
受 S 发送的报文段;
第三次握手:S 确认 C 收到了自己发送的报文段;
3.TCP 和 UDP 的区别
(1)TCP 是面向连接的,UDP 是无连接的即发送数据前不需要先建立链接。
(2)TCP 提供可靠的服务。也就是说,通过 TCP 连接传送的数据,无差错,不
丢失,不重复,且按序到达;UDP 尽最大努力交付,即不保证可靠交付。 并且因
为 tcp 可靠,面向连接,不会丢失数据因此适合大数据量的交换。
(3)TCP 是面向字节流,UDP 面向报文,并且网络出现拥塞不会使得发送速率降
低(因此会出现丢包,对实时的应用比如 IP 电话和视频会议等)。
(4)TCP 只能是 1 对 1 的,UDP 支持 1 对 1,1 对多。
(5)TCP 的首部较大为 20 字节,而 UDP 只有 8 字节。
TCP 是面向连接的可靠性传输,而 UDP 是不可靠的。
4.WebSocket
WebSocket 是 HTML5 中的协议,支持持久连续,http 协议不支持持久性连接。Http1.0 和 HTTP1.1 都不支持持久性的链接,HTTP1.1 中的 keep-alive,将多个http 请求合并为 1 个;
5.BOM
什么是 Bom? Bom 是浏览器对象。有哪些常用的 Bom 属性呢?
(1)location 对象
- location.href – 返回或设置当前文档的 URL
- location.search – 返回 URL 中的查询字符串部分。
例如 http://www.dreamdu.com/dreamdu.php?id=5&name=dreamdu
【返回包括(?)后面的内容?id=5&name=dreamdu 】
-
location.hash–返回URL#后面的内容,如果没有#,返回空
-
location.host – 返回 URL 中的域名部分,
例如 www.dreamdu.com
-
location.hostname – 返回 URL 中的主域名部分,
例如 dreamdu.com
- location.pathname – 返回 URL 的域名后的部分。
例如 http://www.dreamdu.com/xhtml/ 【返回/xhtml/】
- location.port – 返回 URL 中的端口部分。
例如 http://www.dreamdu.com:8080/xhtml/ 【返回 8080】
- location.protocol – 返回 URL 中的协议部分。
例如 http://www.dreamdu.com:8080/xhtml/ 【返回(//)前面的内容 http:】
- location.assign – 设置当前文档的 URL
- location.replace() – 设置当前文档的 URL,并且在 history 对象的地址列表 中移除这个 URL – location.replace(url);
- location.reload() – 重载当前页面
(2)history 对象
- history.go() – 前进或后退指定的页面数 history.go(num);
- history.back() – 后退一页
- history.forward() – 前进一页
(3)Navigator 对象
navigator.userAgent – 返回用户代理头的字符串表示(就是包括浏览器版本
信息等的字符串)
navigator.cookieEnabled – 返回浏览器是否支持(启用)cookie
6.说一下 http2.0
http2.0 是基于 1999 年发布的 http1.0 之后的首次更新。
http2.0相对于http1.0的优势有:
- 提升访问速度(可以对于,请求资源所需时间更少,访问速度更快,相比 http1.0)
- 允许多路复用:多路复用允许同时通过单一的 HTTP/2连接发送多重请求响应信 息。
- 增加了连接数量:在 http1.1 中,浏览器客户端在同一时间,针对同一域名下的请求有一定数量限制(连接数量),超过限制会被阻塞。
- 二进制分帧:HTTP2.0 会将所有的传输信息分割为更小的信息或者帧,并对他们进行二进制编码。
- *首部压缩
- *服务器端推送
7.请求状态码
- 200(成功): 服务器已成功处理了请求
- 304(重定向): 自从上次请求后,请求的网页未被修改过。服务器返回此响应时,不会返回网页内容。
- 400(错误请求): 服务器不理解请求的语法
- 403(禁止请求) 服务器理解请求客户端的请求,但是拒绝执行此请求
- 404(未找到): 服务器找不到请求的网页。
- 401(权限不够):当前请求需要用户验证
- 500(服务器内部错误):服务器遇到错误,无法完成请求。
8.Cookie、sessionStorage、localStorage 的区别
- Cookie:数据始终在同源的 http 请求中携带,可以在浏览器和服务器端来回传递,存储容量小,只有大约 4K 左右;
cookie作用:(1)保存用户登录状态;(2)跟踪用户行为
- sessionStorage:仅在当前浏览器窗口关闭前有效,自然也就不可能持久保持;
- localStorage:始终有效,窗口或浏览器关闭也一直保存,因此用作持久数据;
9.iframe 是什么?有什么缺点?
定义:iframe 元素会创建包含另一个文档的内联框架
提示:可以将提示文字放在<iframe></iframe>之间,来提示某些不支持 iframe的浏览器
缺点:
a. 会阻塞主页面的 onload 事件
b. 搜索引擎无法解读这种页面,不利于 SEO
c. iframe 和主页面共享连接池,而浏览器对相同区域有限制所以会影响性能。
10.Doctype 作用?严格模式与混杂模式如何区分?它们有何意义?
Doctype 声明于文档最前面,告诉浏览器以何种方式来渲染页面,这里有两种模式,严格模式和混杂模式。
- 严格模式的排版和 JS 运作模式是 以该浏览器支持的最高标准运行。
- 混杂模式向后兼容,模拟老式浏览器,防止浏览器无法兼容页面。
11.Cookie 如何防范 XSS 攻击
XSS(跨站脚本攻击)是指攻击者在返回的 HTML 中嵌入 javascript 脚本,为了减轻这些攻击,需要在 HTTP 头部配上,set-cookie:httponly-这个属性可以防止 XSS,它会禁止 javascript 脚本来访问 cookie。secure - 这个属性告诉浏览器仅在请求为 https 的时候发送 cookie。
结果应该是这样的:Set-Cookie=<cookie-value>.....
12.Cookie 和 session 的区别
(1)数据存放位置不同:
cookie数据存放在客户的浏览器上,session数据放在服务器上。
(2)安全程度不同:
cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,考虑到安全应当使用session。
(3)性能使用程度不同:
session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie。
(4)数据存储大小不同:
单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie,而session则存储与服务端,浏览器对其没有限制。
13.说一下你对RESTFUL的理解?
Representational State Transfer的缩写。即"资源表现层状态转化"。
即就是用 URL 定位资源,用 HTTP 描述操作的一种URL设计风格。
举例来说,某个URI是/posts/show/1,其中show是动词,这个URI就设计错了,正确的写法应该是/posts/1,然后用GET方法表示show。
14.讲讲 viewport 和移动端布局
参考答案:
前端开发中,静态网页通常需要适应不同分辨率的设备,常用的自适应解决方案包括媒体查询、百分比、rem 和 vw/vh 等。
下面从 px 单位出发,分析 px 在移动端布局中的不足,接着介绍几种不同的自适应解决方案。
- px 和视口
- 媒体查询
- 百分比自适应场景下的 rem 解决方案
基于750设计稿1rem=100px的布局方案:
html { font-size: calc(100vm / 750 * 100) }
- 通过 vw/vh 来实现自适应
15.http 常用请求头
可以将 http 请求头为通用首部,请求首部,响应首部,实体首部,通用首部表示一些通用信息
- date:表示报文创建时间,请求首部就是请求报文中独有的;
- cookie:和缓存相关的;
- if-Modified-Since:响应首部就是响应报文中独有的;
- set-cookie:和重定向相关的 location, 实体首部用来描述实体部分 ;
- allow:用来描述可执行的请求方法 ;
- content-type:描述主题类型;
- content-Encoding:描述主体的编码方式。
Accept 可接受的响应内容类型(Content-Types) Accept-Charset 可接受的字符集
Accept-Encoding 可接受的响应内容的编码方式
Accept-Language 可接受的响应内容语言列表
Accept-Datetime 可接受的按照时间来表示的响应内容版本
Authorization 用于表示 HTTP
协议中需要认证资源的认证信息
Cache-Control 用来指定当前的请求/回复中的,是否使用缓存机制 Connection 客户端(浏览器)想要优先使用的连接
Cookie 由之前服务器通过 Set-Cookie(见下文)设置的一个 HTTP 协议Cookie
Content-Type 请求体的 MIME 类型(用于 POST 和 PUT请求中)
Date 发送该消息的日期和时间(以 RFC7231中定义的"HTTP 日期"格式发送)
Host 表示服务器的域名以及服务器所监听的端口号。如果所请求的端口是对应的服务的标准端口(80),则端口号可以省略
Origin 发起一个针对跨域资源共享的请求(该请求要求服务器在响应中加入一个
Access-Control-Allow-Origin 的消息头,表示访问控制所允许的来源)
User-Agent 浏览器的身份标识字符串
Warning 一个一般性的警告,表示在实体内容体中可能存在错误
16.强,协商缓存
缓存分为两种:强缓存和协商缓存,根据响应的 header 内容来决定。
- 强缓存相关字段有 expires,cache-control。如果 cache-control 与expires同时存在的话,cache-control 的优先级高于 expires。
- 协商缓存相关字段有Last-Modified/If-Modified-Since,Etag/If-None-Match
17.GET 和 POST 的区别
- get 参数通过 url 传递,post 放在 request body 中。
- get 请求在 url 中传递的参数是有长度限制的,而post 没有。
- get 比 post 更不安全,因为参数直接暴露在 url 中,所以不能用来传递敏感信息。
- get 请求只能进行url 编码,而 post 支持多种编码方式
- get 请求会浏览器主动 cache,而 post 则不支持。
- get请求参数会被完整保留在浏览历史记录里,而 post 中的参数不会被保留。
- GET 和 POST 本质上就是 TCP链接,并无差别。但是由于 HTTP 的规定和浏览器/ 服务器的限制,导致他们在应用过程中体现出一些不同。 GET 产生一个 TCP数据包;POST 产生两个 TCP 数据包
18.如何画一个三角形
三角形原理:边框的均分原理
div {
width:0px;
height:0px;
border-top:10px solid red;
border-right:10px solid transparent;
border-bottom:10px solid transparent;
border-left:10px solid transparent;
}
19.在地址栏里输入一个 URL,到这个页面呈现出来,中间会发生什么?
总体来说分为以下几个过程:
1. DNS解析
2. TCP连接
3. 发送HTTP请求
4. 服务器处理请求并返回HTTP报文
5. 浏览器解析渲染页面
6. 连接结束
输入 url 后,首先需要找到这个 url 域名的服务器 ip,为了寻找这个 ip,浏览器首先会寻找缓存,查看缓存中是否有记录,缓存的查找记录为:浏览器缓存->系统缓存->路由器缓存,缓存中没有则查找系统的 hosts 文件中是否有记录,如果没有则查询 DNS 服务器,得到服务器的 ip 地址后,浏览器根据这个 ip 以及相应的端口号,构造一个 http 请求,这个请求报文会包括这次请求的信息,主要是请求方法,请求说明和请求附带的数据,并将这个 http 请求封装在一个 tcp包中,这个 tcp 包会依次经过传输层,网络层,数据链路层,物理层到达服务器,服务器解析这个请求来作出响应,返回相应的 html 给浏览器,因为 html 是一个树形结构,浏览器根据这个 html 来构建 DOM 树,在 dom 树的构建过程中如果遇到 JS 脚本和外部 JS 连接,则会停止构建 DOM 树来执行和下载相应的代码,这会造成阻塞,这就是为什么推荐 JS 代码应该放在 html 代码的后面,之后根据外部样式,内部样式,内联样式构建一个 CSS 对象模型树 CSSOM 树,构建完成后和DOM 树合并为渲染树,这里主要做的是排除非视觉节点,比如 script,meta 标签和排除 display 为 none 的节点,之后进行布局,布局主要是确定各个元素的位置和尺寸,之后是渲染页面,因为 html 文件中会含有图片,视频,音频等资源,在解析DOM 的过程中,遇到这些都会进行并行下载,浏览器对每个域的并行下载数量有一定的限制,一般是 4-6 个,当然在这些所有的请求中我们还需要关注的就是缓存,缓存一般通过 Cache-Control、Last-Modify、Expires 等首部字段控制。Cache-Control 和 Expires 的区别在于 Cache-Control 使用相对时间,Expires 使用的是基于服务器 端的绝对时间,因为存在时差问题,一般采用Cache-Control,在请求这些有设置了缓存的数据时,会先 查看是否过期,如果没有过期则直接使用本地缓存,过期则请求并在服务器校验文件是否修改,如果上一次 响应设置了ETag值会在这次请求的时候作为If-None-Match的值交给服务器校验,如果一致,继续校验 Last-Modified,没有设置 ETag 则直接验证Last-Modified,再决定是否返回 304。
20.csrf 和 xss 的网络攻击及防范
CSRF:跨站请求伪造
可以理解为攻击者盗用了用户的身份,以用户的名义发送了恶意请求,比如用户登录了一个网站后,立刻在另一个tab页面访问量攻击者用来制造攻击的网站,这个网站要求访问刚刚登陆的网站,并发送了一个恶意请求,这时候 CSRF 就产生了,比如这个制造攻击的网站使用一张图片,但是这种图片的链接却是可以修改数据库的,这时候攻击者就可以以用户的名义操作这个数据库;
防御方式:使用验证码,检查 https 头部的 refer,使用 token
XSS:跨站脚本攻击
是说攻击者通过注入恶意的脚本,在用户浏览网页的时候进行攻击,比如获取 cookie,或者其他用户身份信息,可以分为存储型和反射型,存储型是攻击者输入一些数据并且存储到了数据库中,其他浏览者看到的时候进行攻击,反射型的话不存储在数据库中,往往表现为将攻击代码放在 url地址的请求参数中;
防御方式:为 cookie 设置 httpOnly 属性,对用户的输入进行检查,进行特殊字符过滤;
21.HTML5 和 CSS3 新增的特性?
html5:
1)标签增删
(1) 8 个语义元素 header section footer aside nav main article figure
(2) 内容元素 mark 高亮 progress 进度
(3) 新的表单控件 calander date time email url search
(4) 新的 input 类型 color date datetime datetime-local email
(5) 移除过时标签 big font frame frameset
2)canvas 绘图,支持内联 SVG。支持 MathML
3)多媒体 audio video source embed track
4)本地离线存储,把需要离线存储在本地的文件列在一个 manifest 配置文件
5)web 存储:localStorage、SessionStorage
css3:
边框: border-radius,box-shadow 等;
背景: background-size,background-origin 等;
动画: transform、animation 等。
22.了解重绘和重排(回流)吗,知道怎么去减少重绘和重排吗,让文档脱离文档流有哪些方法?
DOM 的变化影响到了预算内宿的几何属性比如宽高,浏览器重新计算元素的几何属性,其他元素的几何属性也会受到影响,浏览器需要重新构造渲染书,这个过程称之为重排,浏览器将受到影响的部分重新绘制在屏幕上 的过程称为重绘。
引起重排重绘的原因有:
(1) 添加或者删除可见的 DOM 元素,
(2) 元素尺寸位置的改变
(3) 浏览器页面初始化,
(4) 浏览器窗口大小发生改变,重排一定导致重绘,重绘不一定导致重排.
减少重绘重排的方法有:
(1) 不在布局信息改变时做 DOM 查询,
(2) 使用 csstext,className 一次性改变属性
(3) 使用 fragment
(4) 对于多次重排的元素,比如说动画。使用绝对定位脱离文档流,使其不影响其他元素
23.怎么隐藏一个元素
1)opacity:0
该元素隐藏起来了,但不会改变页面布局,并且,如果该元素已经绑定一些事件,如 click 事件,那么点击该区域,也能触发点击事件的
2)visibility:hidden
该元素隐藏起来了,但不会改变页面布局,但是不会触发该元素已经绑定的事件
3)display:none
把元素隐藏起来,并且会改变页面布局,可以理解成在页面中把该元素删除掉。
24.flex布局
容器有以下属性:
- flex-direction: 属性决定主轴的方向;
- flex-wrap: 属性定义,如果一条轴线排不下,如何换行;
- *flex-flow:属性是 flex-direction 属性和 flex-wrap 属性的简写形式,默认值 为 row nowrap;
- justify-content: 属性定义了项目在主轴上的对齐方式。
- align-items: 属性定义项目在交叉轴上如何对齐。
- align-content: 属性定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用。
项目(子元素)也有一些属性:order,flex-grow,flex-shrink,flex-basis,flex,align-self。
-
order 属性定义项目的排列顺序。数值越小,排列越靠前,默认为 0。
-
flex-grow 属性定义项目的放大比例,默认为0,即如果存在剩余空间,也不放 大。
-
flex-shrink 属性定义了项目的缩小比例,默认为 1,即如果空间不足,该项目 将缩小。
-
flex-basis 属性定义了在分配多余空间之前,项目占据的主轴空间(main size)。
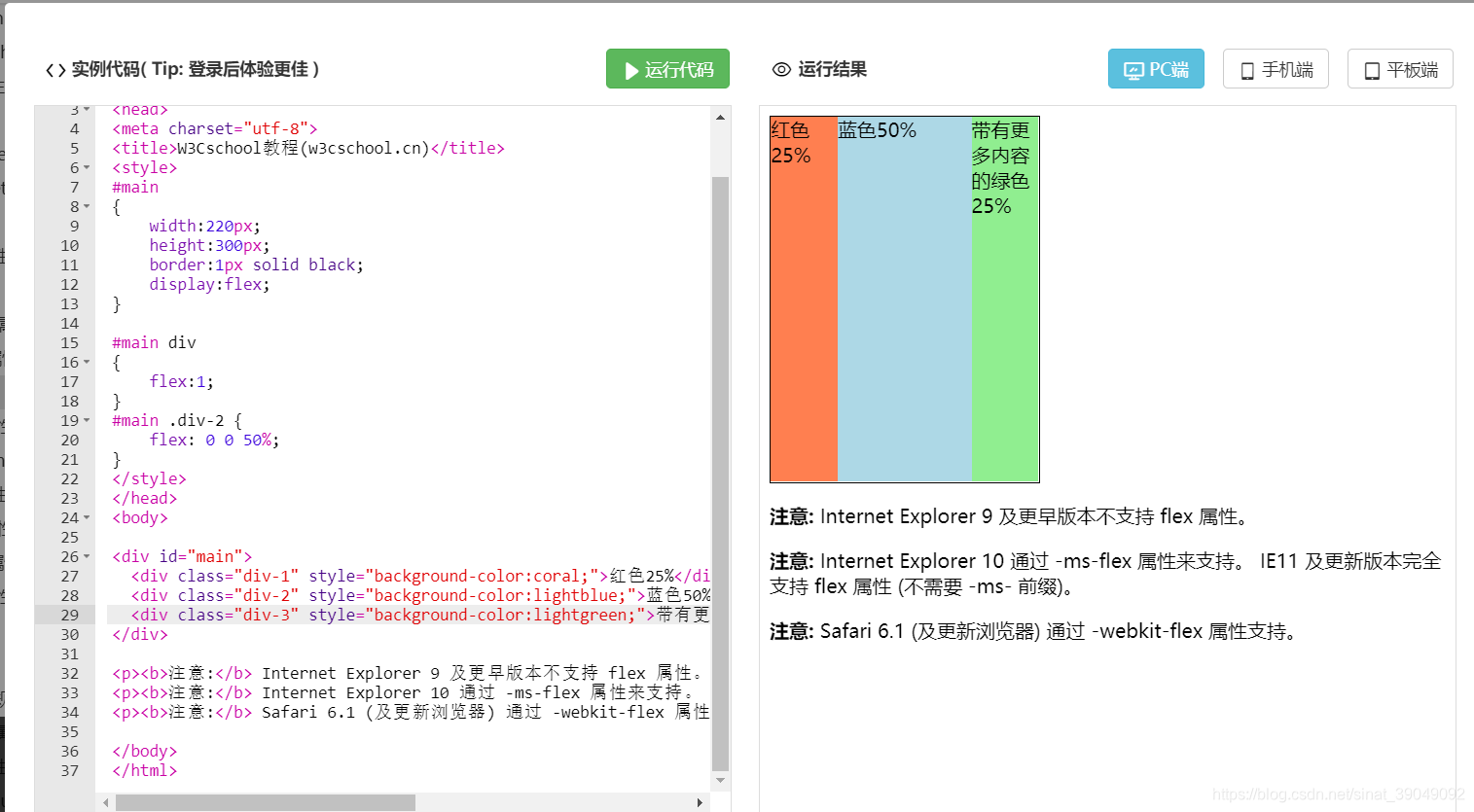
-
flex 属性是 flex-grow、flex-shrink 和 flex-basis 的简写,默认值为 0 1 auto。后两个属性可选。
-
align-self 属性允许单个项目有与其他项目不一样的对齐方式,可覆盖 align-items 属性。默认值为 auto,表示继承父元素的 align-items 属性,如果 没有父元素,则等同于 stretch。
25.说一下类的创建和继承
(1)类的创建(es5):
new 一个 function,在这个 function 的 prototype 里面增加属性和方法。
下面来创建一个 Animal 类:
// 定义一个动物类
function Animal (name) {
// 属性
this.name = name || 'Animal';
// 实例方法
this.sleep = function() {
console.log(this.name + '正在睡觉!');
}
}
// 原型方法
Animal.prototype.eat = function(food) {
console.log(this.name + '正在吃:' + food);
};
这样就生成了一个 Animal 类,实力化生成对象后,有方法和属性。
(2)类的继承——原型链继承
function Cat(){ }
Cat.prototype = new Animal();
Cat.prototype.name = 'cat';
// Test Code
var cat = new Cat();
console.log(cat.name);
console.log(cat.eat('fish'));
console.log(cat.sleep());
console.log(cat instanceof Animal); //true
console.log(cat instanceof Cat); //true
介绍:在这里我们可以看到 new 了一个空对象,这个空对象指向 Animal 并且Cat.prototype 指向了这个空对象,这种就是基于原型链的继承。
特点:基于原型链,既是父类的实例,也是子类的实例
缺点:无法实现多继承
26.如何解决异步回调地狱
promise、generator、async/await
27.说一下事件委托
事件委托指的是,不在事件的发生地(直接 dom)上设置监听函数,而是在其父元素上设置监听函数,通过事件冒泡,父元素可以监听到子元素上事件的触发,通过判断事件发生元素 DOM 的类型,来做出不同的响应。
28.js 的 new 操作符做了哪些事情
new 操作符新建了一个空对象,这个对象原型指向构造函数的 prototype,执行构造函数后返回这个对象。
29.异步加载 js 的方法
defer:只支持 IE 如果您的脚本不会改变文档的内容,可将 defer 属性加入到<script>标签中,以便加快处理文档的速度。因为浏览器知道它将能够安全地读取文档的剩余部分而不用执行脚本,它将推迟对脚本的解释,直到文档已经显示给用户为止。
30.如何理解前端模块化
前端模块化就是复杂的文件编程一个一个独立的模块,比如 js 文件等等,分成独立的模块有利于重用(复用性)和维护(版本迭代),这样会引来模块之间相互依赖的问题,所以有了 commonJS 规范,AMD,CMD 规范等等,以及用于 js 打包(编译等处理)的工具 webpack。
31.js 监听对象属性的改变
参考答案:
我们假设这里有一个 user 对象,
(1)在 ES5 中可以通过 Object.defineProperty 来实现已有属性的监听(Vue2.0)
Object.defineProperty(user,‘name’,{
set:function(key,value){
}
})
缺点:如果 id 不在 user 对象中,则不能监听 id 的变化
(2)在 ES6 中可以通过 Proxy 来实现(Vue3.0)
var user = new Proxy({},{
set:function(target,key,value,receiver){
}
})
这样即使有属性在 user 中不存在,通过 user.id 来定义也同样可以这样监听这个属性的变化哦
32.setTimeout、setInterval 和requestAnimationFrame之间的区别?
requestAnimationFrame 与 setTimeout 和 setInterval 不同,
requestAnimationFrame 不需要设置时间间隔大多数电脑显示器的刷新频率是 60Hz,大概相当于每秒钟重绘 60 次。大多数浏览器都会对重绘操作加以限制,不超过显示器的重绘频率,因为即使超过那个频率用户体验也不会有提升。因此,最平滑动画的最佳循环间隔是1000ms/60,约等于 16.6ms。RAF 采用的是系统时间间隔,不会因为前面的任务,不会影响 RAF,但是如果前面的任务多的话,会响应 setTimeout 和 setInterval 真正运行时的时间间隔。
特点:
(1)requestAnimationFrame 会把每一帧中的所有 DOM 操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率。
(2)在隐藏或不可见的元素中,requestAnimationFrame 将不会进行重绘或回流
这当然就意味着更少的 CPU、GPU 和内存使用量.
requestAnimationFrame 是由浏览器专门为动画提供的 API,在运行时浏览器会自动优化方法的调用,并且如果页面不是激活状态下的话,动画会自动暂停,有效节省了 CPU 开销。
33.promise、process.nextTick、setTimeout代码的执行顺序
setTimeout(function () { console.log(1) }, 0);
new Promise(function (resolve, reject) {
console.log(2);
resolve();
}).then(function () {
console.log(3)
}).then(function () { console.log(4) });
process.nextTick(function () { console.log(5) });
console.log(6);
//输出 2,6,5,3,4,1
34.Function.proto(getPrototypeOf)是什么?
获取一个对象的原型,在 chrome 中可以通过_proto_的形式,或者在 ES6 中可以通过 Object.getPrototypeOf 的形式。
那么 Function.proto 是什么么?也就是说 Function 由什么对象继承而来,我们来做如下判别。
Function.__proto__==Object.prototype //false
Function.__proto__==Function.prototype//true
我们发现 Function 的原型也是 Function。
35.实现 js 中所有对象的深度克隆(包装对象,Date 对象,正则对象)
通过递归可以简单实现对象的深度克隆,但是这种方法不管是ES6还是ES5实现,都有同样的缺陷,就是只能实现特定的 object 的深度复制(比如数组和函数),不能实现包装对象 Number,String , Boolean,以及 Date 对象,RegExp 对象的复制。
(1)前文的方法
function deepClone(obj){
var newObj= obj instanceof Array ? [] : {};
for(var i in obj){
newObj[i] = typeof obj[i] == 'object'?
deepClone(obj[i]):obj[i];
}
return newObj;
}
这种方法可以实现一般对象和数组对象的克隆,比如:
var arr=[1,2,3];
var newArr = deepClone(arr);
// newArr->[1,2,3]
var obj={
x:1,
y:2
}
var newObj=deepClone(obj);
// newObj={x:1,y:2}
但是不能实现例如包装对象 Number,String,Boolean,以及正则对象 RegExp 和Date 对象的克隆,比如:
//Number 包装对象
var num = new Number(1);
typeof num // "object"
var newNum = deepClone(num);
//newNum -> {} 空对象
//String 包装对象
var str = new String("hello");
typeof str //"object"
var newStr = deepClone(str);
//newStr-> {0:'h',1:'e',2:'l',3:'l',4:'o'};
//Boolean 包装对象
var bol = new Boolean(true);
typeof bol //"object"
var newBol = deepClone(bol);
// newBol ->{} 空对象
....
(2)valueof()函数
所有对象都有 valueOf 方法,valueOf 方法对于:如果存在任意原始值,它就默认将对象转换为表示它的原始值。对象是复合值,而且大多数对象无法真正表示为一个原始值,因此默认的 valueOf()方法简单地返回对象本身,而不是返回一个原始值。数组、函数和正则表达式简单地继承了这个默认方法,调用这些类型的实例的 valueOf()方法只是简单返回这个对象本身。
对于原始值或者包装类:
function baseClone(base){
return base.valueOf();
}
//Number
var num = new Number(1);
var newNum = baseClone(num);
//newNum->1
//String
var str = new String('hello');
var newStr = baseClone(str);
// newStr->"hello"
//Boolean
var bol = new Boolean(true);
var newBol = baseClone(bol);
//newBol-> true
其实对于包装类,完全可以用=号来进行克隆,其实没有深度克隆一说,这里用 valueOf 实现,语法上比较符合规范。
对于 Date 类型:
因为 valueOf 方法,日期类定义的 valueOf()方法会返回它的一个内部表示:1970年 1 月 1 日以来的毫秒数.因此我们可以在 Date 的原型上定义克隆的方法:
Date.prototype.clone=function(){
return new Date(this.valueOf());
}
var date = new Date('2010');
var newDate = date.clone();
// newDate-> Fri Jan 01 2010 08:00:00 GMT+0800
对于正则对象 RegExp:
RegExp.prototype.clone = function() {
var pattern = this.valueOf();
var flags = '';
flags += pattern.global ? 'g' : '';
flags += pattern.ignoreCase ? 'i' : '';
flags += pattern.multiline ? 'm' : '';
return new RegExp(pattern.source, flags);
};
var reg = new RegExp('/111/');
var newReg = reg.clone();
//newReg-> /\/111\//
36.箭头函数中 this 指向举例
定义时绑定
var a=11;
function test2(){
this.a=22;
let b=()=>{console.log(this.a)}
b();
}
var x=new test2();
//输出 22
var a = 11;
function test2(a) {
this.a = a = 22;
// let b = () => { console.log(this.a) }
let b = function () {
console.log(this.a)
}
b();
}
var x = new test2();
console.log('x:', x);
//11,
//x:22
var a = 11;
function test2(a) {
this.a = a = 22;
let b = () => { console.log(this.a) }
/* let b = function () {
console.log(this.a)
} */
b();
}
var x = new test2();
console.log('x:', x);
//22
//x:22
37.js 判断类型
判断方法:typeof(),instanceof,Object.prototype.toString.call()
typeof
常用于判断基本数据类型:number,string,undefined,boolean,null(object),symbol(ES6新增) 五种
例如:
var test1= 1;
alert(typeof test1);//输出number
var test2 = "";
alert(typeof test2);//输出string
var test3 = undefined;
alert(typeof test3);//输出undefined
var test4 = true;
alert(typeof test4);//输出boolean
undefined: Undefined类型,当一个声明了一个变量未初始化时,得到的就是undefined。
null是javascript的关键字,可以认为是对象类型,它是一个空对象指针,和其它语言一样都是代表“空值”,不过 undefined 却是javascript才有的。
undefined是在ECMAScript第三版引入的,为了区分空指针对象和未初始化的变量,它是一个预定义的全局变量。没有返回值的函数返回为undefined,没有实参的形参也是undefined。
instanceof
instanceof 用于判断一个变量是否某个对象的实例,
引用数据类型 :常见的Object Array Function 其实 在JS中除了基本数据类型以外的都是对象,数据是对象,函数是对象,正则表达式是对象)
- 用法:变量名 instanceof Object、Array、Function
- 返回值: 是一个布尔值
var a = {};
var b = [];
var c = function () {};
//a b c 都是 Object 的实例
console.log(a instanceof Object) //true
console.log(b instanceof Object) //true
console.log(c instanceof Object) //true
//只有 Array 类型的 b 才是 Array 的实例
console.log(a instanceof Array) //false
console.log(b instanceof Array) //true
console.log(c instanceof Array) //false
//只有 Function 类型的 c 才是 Function 的实例
console.log(a instanceof Function) //false
console.log(b instanceof Function) //false
console.log(c instanceof Function) //true
Object.prototype.toString.call()
- 用法:Object.prototype.toString.call(value)
- 这是对象的一个原生原型扩展函数,用来精确的区分数据类型…
console.log(Object.prototype.toString.call(123)) //[object Number]
console.log(Object.prototype.toString.call('123')) //[object String]
console.log(Object.prototype.toString.call(true)) //[object Boolean]
console.log(Object.prototype.toString.call(undefined)) //[object Undefined]
console.log(Object.prototype.toString.call([])) //[object Array]
console.log(Object.prototype.toString.call(function(){})) //[object Function]
console.log(Object.prototype.toString.call({})) //[object Object]
38.数组常用方法
- push() :向数组结尾处添加一个新的元素;
- join() :将所有数组元素结合为一个字符串;
- pop():删除数组中最后一个元素;
- shift():删除首个数组元素(并把所有其他元素“位移”到更低的索引);
- unshift():向数组开头添加新元素;
- splice():可用于向数组添加新项;删除数组元素;
可用于向数组添加新项
var fruits = ["Banana", "Orange", "Apple", "Mango"];
fruits.splice(2, 0, "Lemon", "Kiwi");
console.log(fruits) //Banana,Orange,Lemon,Kiwi,Apple,Mango
删除数组元素 [方法返回一个包含已删除项的数组]
var fruits = ["Banana", "Orange", "Apple", "Mango"];
var removed = fruits.splice(2, 2, "Lemon", "Kiwi");
//console.log(fruits) //Banana,Orange,Lemon,Kiwi
//console.log(removed) //Apple,Mango
使用 splice() 来删除元素
通过聪明的参数设定,您能够使用 splice() 在数组中不留“空洞”的情况下移除元素:
var fruits = ["Banana", "Orange", "Apple", "Mango"];
fruits.splice(0, 1); // 删除 fruits 中的第一个元素
- concat():通过合并(连接)现有数组来创建一个新数组
实例(合并两个数组)
var myGirls = ["Cecilie", "Lone"];
var myBoys = ["Emil", "Tobias", "Linus"];
var myChildren = myGirls.concat(myBoys); // 连接 myGirls 和 myBoys
实例(合并三个数组)
var arr1 = ["Cecilie", "Lone"];
var arr2 = ["Emil", "Tobias", "Linus"];
var arr3 = ["Robin", "Morgan"];
var myChildren = arr1.concat(arr2, arr3); // 将arr1、arr2 与 arr3 连接在一起
实例(将数组与值合并)
var arr1 = ["Cecilie", "Lone"];
var myChildren = arr1.concat(["Emil", "Tobias", "Linus"]);
- slice():用数组的某个片段切出新数组。
一个参数:从数组元素 n(“Apple”)开始切出一段数组
var fruits = ["Banana", "Orange", "Lemon", "Apple", "Mango"];
var citrus = fruits.slice(3);
console.log(citrus) //Apple,Mango
两个参数,比如 (1, 3)。该方法会从开始参数选取元素,直到结束参数(不包括)为止。
var fruits = ["Banana", "Orange", "Lemon", "Apple", "Mango"];
var citrus = fruits.slice(1, 3);
console.log(citrus) //Apple,Mango
- toString():自动把数组转换为字符串
var fruits = ["Banana", "Orange", "Apple", "Mango"];
var fruitString = fruits.toString();
console.log(fruitString) // Banana,Orange,Apple,Mango
- sort():方法以字母顺序对数组进行排序;
var fruits = ["Banana", "Orange", "Apple", "Mango"];
fruits.sort();
console.log(fruits) //["Apple", "Banana", "Mango", "Orange"]
- reverse():反转数组中的元素
var fruits = ["Banana", "Orange", "Apple", "Mango"];
console.log(fruits) //[ "Mango", "Apple", "Orange", "Banana" ]
- map():返回一个新数组,数组中的元素为原始数组元素调用函数处理后的值。
var num = [1, 2, 3];
var newNum = num.map((ele, index) => {
return ele + 3
})
console.log(newNum); // 4,5,6
39.es6数组方法
- forEach():会遍历数组, 没有返回值, 不允许在循环体内写return, 不会改变原来数组的内容;
- map():遍历数组, 会返回一个新数组, 不会改变原来数组里的内容
let array = [1, 2, 3, 4];
let temp = array.map((item, index, array) => {
return item * 10;
});
console.log(temp); // [10, 20, 30, 40];
console.log(array); // [1, 2, 3, 4]
- filter():会过滤掉数组中不满足条件的元素, 把满足条件的元素放到一个新数组中, 不改变原数组;
let array = [1,2,3,4];
let temp = array.filter((item, index, array) =>{
return item >3;
});
console.log(temp);// [4]
console.log(array);// [1, 2, 3, 4]
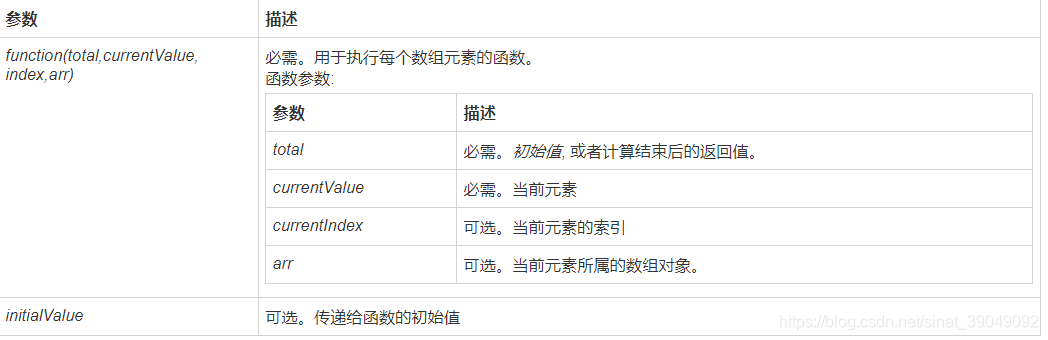
- reduce():接收一个函数作为累加器,数组中的每个值(从左到右)开始缩减,最终计算为一个值。reduce()方法接受四个参数:初始值(或者上一次回调函数的返回值),当前元素值,当前索引,调用 reduce() 的数组。
array.reduce(function(total, currentValue, currentIndex, arr), initialValue)
(1)数组求和
var total = [ 0, 1, 2, 3 ].reduce(( acc, cur ) => {
return acc + cur
}, 0);
console.log(total) // 6
(2)二维数组转为一维数组
var array = [[1, 2], [3, 4], [5, 6]].reduce(( acc, cur ) => {
return acc.concat(cur)
}, []);
console.log(array) // [ 0, 1, 3, 4, 5, 6 ]
(3)计算数组中每个元素出现的次数
let names = ['tom', 'jim', 'jack', 'tom', 'jack'];
const countNames = names.reduce((allNames, name) => {
if (name in allNames) {
allNames[name] ++;
}
else {
allNames[name] = 1;
}
return allNames;
}, {});
console.log(countNames) // { tom: 2, jim: 1, jack: 2 }
40.JS 实现跨域
- JSONP : 通 过 动 态 创 建 script , 再 请 求 一 个 带 参 网 址 实 现 跨 域 通 信 。
- document.domain + iframe 跨域:两个页面都通过 js 强制设置 document.domain为基础主域,就实现了同域。
- location.hash + iframe 跨域:a 欲与 b 跨域相互通信,通过中间页 c 来实现。三个页面,不同域之间利用 iframe 的 location.hash 传值,相同域之间直接 js访问来通信。
- window.name + iframe 跨域:通过 iframe 的 src 属性由外域转向本地域,跨域数据即由 iframe 的 window.name 从外域传递到本地域。
- postMessage 跨域:可以跨域操作的 window 属性之一。
- CORS:服务端设置 Access-Control-Allow-Origin 即可,前端无须设置,若要带cookie 请求,前后端都需要设置。
- 代理跨域:启一个代理服务器,实现数据的转发
41.null == undefined 为什么
要比较相等性之前,不能将 null 和 undefined 转换成其他任何值,但 null ==undefined 会返回 true 。ECMAScript 规范中是这样定义的。
null和undefined都是js的基本数据类型,都是代表者一个不可用的值(即是空),而双等于是判断两个数的值,所以双等于返回的是true,而三等于要判断值和类型,对于数据类型而言这两个不是同一类型,所以三等于返回的是false
为什么null值和undefind的值相等。这里又顺便提了一下js的原型,在js的原型链上,null是最上层的,undefind最终的指向也是null,所以他们的值是相等的
42. 强制类型转换
1.定义:指将一个数据类型强制转换为其他的数据类型,类型转换主要指,将其他的数据类型,转换为String ,Number, Boolean。
2.将其他的数据类型转换为Number
方式一:使用number()函数
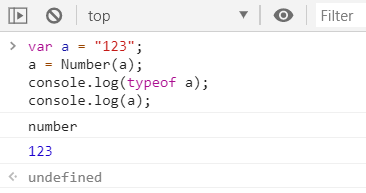
- 字符串 -----> 数字
1.如果是纯数字的字符串,则直接将其转换为数字
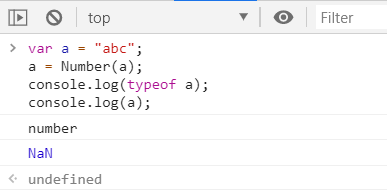
2.如果字符串中有非数字的内容,则转换为NaN
3.如果字符串是一个空串或者是一个全是空格的字符串,则转换为0
- 布尔 ------> 数字
1.true 转成 1
2.false 转成 0
-null ------> 数字 0
-undefind ------> 数字 NaN
★具体示例:
▶ - 字符串 -----> 数字
①纯数字的字符串
②字符串中有非数字的内容
③字符串是一个空串或者是一个全是空格的字符串
▶一个空串
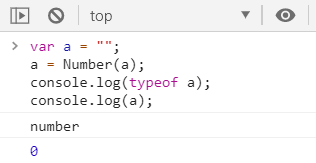
▶一个全是空格的字符串
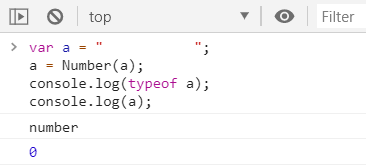
▶ - 布尔 ------> 数字
①true 转成 1
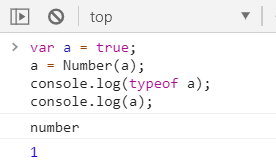
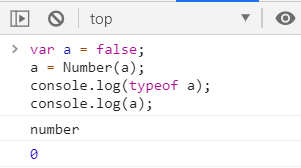
②false 转成 0
▶ -null ------> 数字 0
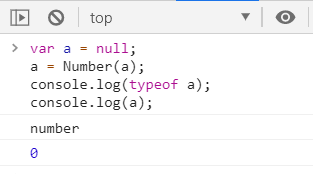
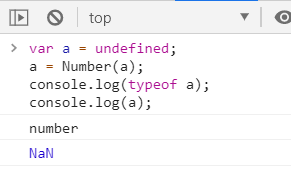
▶ -undefind ------> 数字 NaN
⑵方式二:这种方法专门用来对付字符串
- parseInt()把一个字符串转换为一个整数
- parseFloat()把一个字符串转换为一个浮点数
★具体示例:
①调用parseInt()函数将a转换为Number
parseInt()可以将一个字符串中的有效的整数内容取出来,然后转换为Number
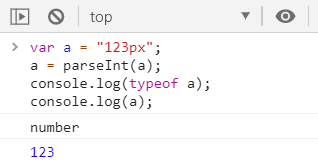
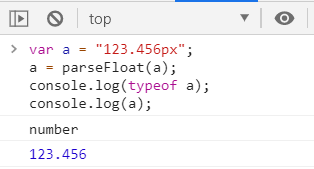
②调用parseFloat()将a转换为Number
parseFloat()作用和parseInt()类似,不同的是它可以获得有效的小数
③如果对非String使用parseInt()或parseFloat,
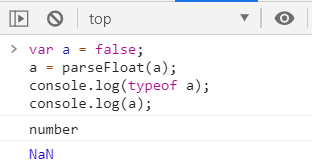
它会先将其转换为String然后再操作
▶非String使用parseInt()
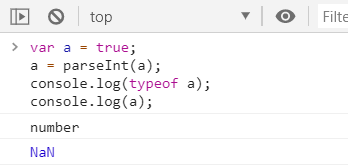
▶非String使用parseFloat
参考链接:https://www.cnblogs.com/shihaiying/p/11872298.html
43.能来讲讲 JS 的语言特性吗
- 运行在客户端浏览器上;
- 不用预编译,直接解析执行代码;
- 是弱类型语言,较为灵活;
- 与操作系统无关,跨平台的语言;
- 脚本语言、解释性语言
44.判断一个数组
- Object.prototype.call.toString()
- Instanceof:object instanceof Array
45.this 的指向 哪几种
- 默认绑定:全局环境中,this 默认绑定到 window。
- 隐式绑定:一般地,被直接对象所包含的函数调用时,也称为方法调用,this隐式绑定到该直接对象。
- 隐式丢失:隐式丢失是指被隐式绑定的函数丢失绑定对象,从而默认绑定到window。
- 显式绑定:通过call()、apply()、bind()方法把对象绑定到 this 上,叫做显式绑定。
- new 绑定:如果函数或者方法调用之前带有关键字new,它就构成构造函数调用。对于 this 绑定来说,称为 new 绑定。
46.JS 中继承实现的几种方式
1)原型链继承
将父类的实例作为子类的原型,他的特点是实例是子类的实例也是父类的实例,父类新增的原型方法/属性,子类都能够访问,并且原型链继承简单易于实现,缺点是来自原型对象的所有属性被所有实例共享,无法实现多继承,无法向父类构造函数传参。
2)构造继承
使用父类的构造函数来增强子类实例,即复制父类的实例属性给子类,构造继承可以向父类传递参数,可以实现多继承,通过 call 多个父类对象。但是构造继承只能继承父类的实例属性和方法,不能继承原型属性和方法,无法实现函数复用,每个子类都有父类实例函数的副本,影响性能。
3)实例继承
为父类实例添加新特性,作为子类实例返回,实例继承的特点是不限制调用方法,不管是 new 子类()还是子类()返回的对象具有相同的效果,缺点是实例是父类的实例,不是子类的实例,不支持多继承。
4)拷贝继承
特点:支持多继承,缺点:效率较低,内存占用高(因为要拷贝父类的属性)无法获取父类不可枚举的方法(不可枚举方法,不能使用 for in 访问到)。
5)组合继承
通过调用父类构造,继承父类的属性并保留传参的优点,然后通过将父类实例作为子类原型,实现函数复用。
6)寄生组合继承
通过寄生方式,砍掉父类的实例属性,这样,在调用两次父类的构造的时候,就不会初始化两次实例方法/属性,避免的组合继承的缺点。
47.let const var 的区别 ,什么是块级作用域,如何用ES5 的方法实现块级作用域(立即执行函数),ES6 呢?
提起这三个最明显的区别是 :
- var 声明的变量是全局或者整个函数块的,而let,const 声明的变量是块级的变量;
- var 声明的变量存在变量提升,let,const不存在;
- let 声明的变量允许重新赋值,const 不允许。
48.基本数据类型和引用数据类的区别?
- 基本数据类型的值是不可变的;
- 基本数据类型不可以添加属性和方法,但是引用类型可以;
- 基本数据类型的赋值是简单赋值,引用数据类型的赋值是对象引用;
- 基本数据类型的比较是值的比较,引用类型的比较是引用的比较,比较对象的内存地址是否相同;
- 基本数据类型是存放在栈区的,引用数据类型同事保存在栈区和堆区;
49. NaN 是什么的缩写?
NaN 是 JS 中的特殊值,表示非数字,NaN 不是数字,但是他的数据类型是数字(Number)。它不等于任何值,包括自身,在布尔运算时被当做 false,NaN 与任何数运算得到的结果都是 NaN,当然算失败或者运算无法返回正确的数值的就会返回 NaN,一些数学函数的运算结果也会出现 NaN。
50.JS 的作用域类型:
一般认为的作用域是词法作用域,此外 JS 还提供了一些动态改变作用域的方法
常见的作用域类型有:
1)函数作用域:如果在函数内部我们给未定义的一个变量赋值,这个变量会转变成为一个全局变量。
2)块作用域:块作用域吧标识符限制在{}中。
51.了解事件代理吗,这样做有什么好处?
事件代理/事件委托:利用了事件冒泡,只指定一个事件处理程序,就可以管理某一类型的事件
简而言之:事件代理就是说我们将事件添加到本来要添加的事件的父节点,将所有子节点需要绑定的事件委托给父节点来触发处理函数,这通常会使用在大量的同级元素需要添加同一类事件的时候,比如一个动态的非常多的列表,需要为每个列表项都添加点击事件,这时就可以使用事件代理,通过判断 e.target.nodeName 来判断发生的具体元素,这样做的好处是减少事件绑定,同时动态的 DOM 结构仍然可以监听,事件代理发生在冒泡阶段。
52.什么是进程 线程
进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程:是进程的一部分,一个没有线程的进程可以被看作是单线程的。线程有时又被称为轻权进程或轻量级进程,也是 CPU 调度的一个基本单位。
四、算法与数据结构
1. 二叉树层序遍历
//思路:先建立一棵二叉树。再进行队列遍历
function tree(obj) {
var obj = obj.split(')');
obj.pop();
var newobj = [];
for (var i = 0; i < obj.length; i++) {
newobj.push(obj[i].replace('(', ''));
}
var root = {
value: null, left: null, right: null, have: 0
}
var u;
for (var i = 0; i < newobj.length; i++) {
var a1 = newobj[i].split(',')[0];
var a2 = newobj[i].split(',')[1];
u = root;
if (a2 !== '') {
for (var j = 0; j < a2.length; j++) {
if (a2[j] === 'L') {
if (u.left === null) {
u.left = newnode();
u = u.left;
} else {
u = u.left;
}
} else if (a2[j] === 'R') {
if (u.right === null) {
u.right = newnode();
u = u.right;
} else {
u = u.right;
}
}
}
if (u.have === 1) {
} else {
u.value = a1;
u.have = 1;
}
} else {
root.value = a1;
u.have = 1;
}
}
return root;
}
//建立新结点
function newnode() {
return { value: null, left: null, right: null, have: 0 };
}
//队列遍历
function bfs() {
var root =
tree('(11,LL)(7,LLL)(8,R)(5,)(4,L)(13,RL)(2,LLR)(1,RRR)(4,RR)');
var front = 0, rear = 1, n = 0;
var q = [], ans = [];
q[0] = root;
while (front < rear) {
var u = q[front++];
if (u.have !== 1) {
return;
}
ans[n++] = u.value;
if (u.left !== null) {
q[rear++] = u.left;
}
if (u.right !== null) {
q[rear++] = u.right;
}
}
console.log(ans.join(' '));
}
bfs();
2.尾递归
如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的。当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归。
3.如何写一个大数阶乘?递归的方法会出现什么问题?
function factorial(n){
return n > 1 ? n * factorial(n-1) : 1;
}
递归方法会有计算溢出的问题
4.把多维数组变成一维数组的方法
用到之前提的数组扁平化方法
5.知道的排序算法 说一下冒泡快排的原理
冒泡排序:重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序(如从大到小、首字母从 A 到 Z)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素已经排序完成。
快速排序:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
6.数组去重(见前文)
7.排序数组,输出前 10 个
8.知道数据结构里面的常见的数据结构?
常见的数据结构有链表,栈,队列,树,更深一点的就还有图
9.找出数组中第 k 大的数组出现多少次,比如数组【1,2,4,4,3,5】第二大的数字是 4,出现两次,所以返回 2
10.合并两个有序数组
11.给一个数,去一个已经排好序的数组中寻找这个数的位置(通过快速查找,二分查找)
五、其他前端知识
1.重绘和回流
回流
当render tree中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建。这就称为回流(reflow)。每个页面至少需要一次回流,就是在页面第一次加载的时候,这时候是一定会发生回流的,因为要构建render tree。在回流的时候,浏览器会使渲染树中受到影响的部分失效,并重新构造这部分渲染树,完成回流后,浏览器会重新绘制受影响的部分到屏幕中,该过程成为重绘。
重绘
当render tree中的一些元素需要更新属性,而这些属性只是影响元素的外观,风格,而不会影响布局的,比如background-color。则就叫称为重绘。
2. 0.1 + 0.2 === 0.3 嘛?为什么?
JavaScirpt 使用 Number 类型来表示数字(整数或浮点数),遵循 IEEE 754 标准,通过 64 位来表示一个数字(1 + 11 + 52)
- 1 符号位,0 表示正数,1 表示负数 s
- 11 指数位(e)
- 52 尾数,小数部分(即有效数字)
在两数相加时,会先转换成二进制,0.1 和 0.2 转换成二进制的时候尾数会发生无限循环,然后进行对阶运算,JS 引擎对二进制进行截断,所以造成精度丢失。
所以总结:精度丢失可能出现在进制转换和对阶运算中
3.前端性能优化的方法?
- 减少 http 请求次数:CSS Sprites,JS、CSS 源码压缩、图片大小控制合适; 网页 Gzip,CDN托管,data 缓存,图片服务器。
- 前端模板 JS+数据,减少由于 HTML 标签导致的带宽浪费,前端用变量保存 AJAX请求结果,每次操作本地变量,不用请求,减少请求次数
- 用 innerHTML 代替 DOM 操作,减少 DOM 操作次数,优化javascript 性能。
- 当需要设置的样式很多时设置 className 而不是直接操作 style。
- 少用全局变量、缓存 DOM 节点查找的结果。减少 IO 读取操作。
- 避免使用 CSS Expression(css表达式)又称 Dynamic properties(动态属 性)。
- 图片预加载,将样式表放在顶部,将脚本放在底部 加上时间戳。
- 使用雪碧图
- 使用图片懒加载,lazyload.js、vue-lazyload
4.js判断一个字符串是否是回文字符串
这里用递归算法实现
function palindRome(str){
var len = str.length;
var str1 = "";
for(var i=len-1; i>=0;i--){
str1+=str[i];
}
console.log(str1 == str)
}
palindRome("abcba");//true
palindRome("abcbac");//false
5.数组去重
(1)使用双重for循环,再利用数组的splice方法去重(ES5常用)
注:array.splice(index,howmany)
用于添加或删除数组中的元素,返回含有被删除的元素的数组。如果未删除任何元素,则返回空数组。
let arr = [1,5,6,0,7,3,0,5,9,5,5]
function unique (arr) {
for (let i = 0, len = arr.length; i < len; i++) {
for (let j = i + 1, len = arr.length; j < len; j++) {
if (arr[i] === arr[j]) {
arr.splice(j,1) // arr删除重复元素
j-- // 每删除一个数j的值就减1
}
}
}
return arr
}
console.log(unique(arr)) // [1,5,6,0,7,3,9]
(2)利用数组的indexOf方法去重
注:array.indexOf(item,statt) 返回数组中某个指定的元素的位置,没有则返回-1。
let arr = [1,-5,-4,0,-4,7,7,3]
function unique (arr) {
let arr1 = []
for (let i = 0, len = arr.length; i < len ; i++) {
if (arr1.indexOf(arr[i]) === -1) {
arr1.push(arr[i])
}
}
return arr1
}
console.log(unique(arr))
(3)利用数组的sort方法去重(相邻元素对比法)【冒泡】
注:先对arr进行sort排序,再对排序后的数组进行相邻元素比较
let arr = [5,7,1,8,1,8,3,4,9,7]
function unique (arr) {
arr = arr.sort()
console.log('arr', arr)
let arr1 = [arr[0]] // 赋初始值
for (let i = 1; i < arr.length; i++) {
if (arr[i] !== arr[i-1]) {
arr1.push(arr[i])
}
}
return arr1
}
console.log(unique(arr))
(4)利用ES6中的 Set 方法去重
let arr = [1,5,4,1,5,3,8,0]
function unique (arr) {
return Array.from(new Set(arr)) // Array.from()方法就是将一个类数组对象或者可遍历对象转换成一个真正的数组
}
console.log(unique(arr))
//或者
console.log([...new Set(arr)])
(5)* 利用 reduce方法去重
注:array.reduce(function(accumulator, currentValue, currentIndex,
array), initialValue)
initialValue:初始值(可选)
accumulator: reduce方法多次执行的累积结果。若有提供initialValue,则第一次循环时 accumulator 的值便为nitialValue;若未提供initialValue,第一次循环时 accumulator 的值为数组第一项arr[0]。(必需)
currentValue:数组循环当前处理的值。若有提供 initialValue,第一次循环currentValue的值为数组第一项arr[0];若未提供initialValue,第一次循环由于arr[0]成了accumulator 的值,所以currentValue 只能从arr[1]开始。(必需)
currentIndex:数组循环当前处理值的索引。
array:当前正在被循环的数组。
let arr = [1,6,4,null,9,null,1]
var newArr = arr.reduce((prev,cur) => {
prev.indexOf(cur) === -1 && prev.push(cur);
return prev;
}, [])
console.log(newArr)
(6)利用数组的filter方法去重
// 结合indexOf方法,indexOf返回在数组中可以找到一个给定元素的第一个索引
let arr = [1,2,2,4,null,null]
let newArr = arr.filter((item,index,arr) => {
return arr.indexOf(item) === index // 找到在arr中有的对应item,并返回
})
console.log(newArr)
(7)利用数组的includes去重
注:arr.includes(指定元素(必填),指定索引值(可选,默认值为0) ),有值返回true,没有则返回false
let arr = [-1,0,8,-3,-1,5,5,7]
function unique (arr) {
let arr1 = []
for (let i = 0,len = arr.length; i < len; i++) {
if (!arr1.includes(arr[i])) { // 检索arr1中是否包含arr中的值
arr1.push(arr[i])
}
}
return arr1
}
console.log(unique(arr))
(8)利用ES6中的Map方法去重
创建一个空Map数据结构,遍历需要去重的数组,把数组的每一个元素作为key存到Map中。由于Map中不会出现相同的key值,所以最终得到的就是去重后的结果。
let arr = [1,0,8,3,-9,1,0,-9,7]
function unique (arr) {
let map = new Map()
console.log(map)
let arr1 = []
for (let i = 0, len = arr.length; i < len; i ++) {
if (map.has(arr[i])) { // 判断map是否存在该key值
map.set(arr[i], true)
console.log('map1', map) // {1:true, 0: true, 8: false, 3:false, -9: true, 7:false}
} else {
map.set(arr[i], false)
console.log('map2', map) // {1:false, 0: false, 8: false, 3:false, -9: false, 7:false}
arr1.push(arr[i])
}
}
return arr1
}
console.log(unique(arr))
(9)* 利用函数递归去重
let arr = [1,1,5,6,0,9,3,0,6]
function unique (arr) {
let arr1 = arr;
let len = arr.length;
arr1.sort((a,b) => {
return a-b // 从小到大排序
})
function loop (index) {
if (index >= 1) {
if (arr1[index] === arr1[index-1]) {
arr1.splice(index,1)
}
loop(index - 1)
}
}
loop(len - 1) // index初始值为len-1,倒序
return arr1
}
console.log(unique(arr))
6.接受参数n=5,不用for循环输出数组【1,2,3,4,5】
function show(n) {
var arr = [];
return (function fn() {
arr.unshift(n);
n--;
if (n != 0) {
fn();
}
return arr;
})()
}
show(5)//[1,2,3,4,5]
7.计算数组中每个元素出现的次数
let names = ['tom', 'jim', 'jack', 'tom', 'jack'];
const countNames = names.reduce((allNames, name) => {
if (name in allNames) {
allNames[name] ++;
}
else {
allNames[name] = 1;
}
return allNames;
}, {});
console.log(countNames) // { tom: 2, jim: 1, jack: 2 }
8.如何实现 sleep 的效果
(1)通过 promise 来实现
function sleep(ms){
var temple=new Promise(
(resolve)=>{
console.log(111);setTimeout(resolve,ms)
});
return temple
}
sleep(500).then(function(){
//console.log(222)
})
//先输出了 111,延迟 500ms 后输出 222
(2)通过 async 封装
function sleep(ms){
return new Promise((resolve)=>setTimeout(resolve,ms));
}
async function test(){
var temple=await sleep(1000);
console.log(1111)
return temple
}
test();
//延迟 1000ms 输出了 1111
9.Function.proto(getPrototypeOf)是什么?
获取一个对象的原型,在 chrome 中可以通过_proto_的形式,或者在 ES6 中可以通过 Object.getPrototypeOf 的形式。
那么 Function.proto 是什么?也就是说 Function 由什么对象继承而来,我们来做如下判别。
Function.__proto__==Object.prototype //false
Function.__proto__==Function.prototype//true
我们发现 Function 的原型也是 Function。
10.去除字符串首尾空格
使用正则(^\s*)|(\s*$)即可
11.有一个游戏叫做 Flappy Bird,就是一只小鸟在飞,前面是无尽的沙漠,上下不断有钢管生成,你要躲避钢管。然后小明在玩这个游戏时候老是卡顿甚至崩溃,说出原因(3-5个)以及解决办法(3-5 个)
原因可能是:
- 1)内存溢出问题。
- 2)资源过大问题。
- 3)资源加载问题。
- 4)canvas 绘制频率问题
解决办法:
1)针对内存溢出问题,我们应该在钢管离开可视区域后,销毁钢管,让垃圾收集器回收钢管,因为不断生成的钢管不及时清理容易导致内存溢出游戏崩溃。
2)针对资源过大问题,我们应该选择图片文件大小更小的图片格式,比如使用webp、png 格式的图片,因为绘制图片需要较大计算量。
3)针对资源加载问题,我们应该在可视区域之前就预加载好资源,如果在可视区域生成钢管的话,用户的体验就认为钢管是卡顿后才生成的,不流畅。
4)针对 canvas 绘制频率问题,我们应该需要知道大部分显示器刷新频率为 60次/s,因此游戏的每一帧绘制间隔时间需要小于 1000/60=16.7ms,才能让用户觉得不卡顿。
12.说一下什么是 virtual dom
用 JavaScript 对象结构表示 DOM 树的结构;然后用这个树构建一个真正的DOM 树,插到文档当中 当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两棵树差异 把所记录的差异应用到所构建的真正的 DOM 树上,视图就更新了。Virtual DOM 本质上就是在 JS 和 DOM 之间做了一个缓存。
13.写一个函数,第一秒打印 1,第二秒打印 2
for(let i=0;i<5;i++){
setTimeout(function(){
console.log(i)
}, 1000*i)
}
由这道题我们可以抛出问题:for循环中的var和let的区别?为什么?
我们先来看一个例子:
for (var i = 0; i < 3; i++) {
setTimeout(function () {
console.log(i) // 3s 后输出 3次3
}, 30 * 100)
console.log(i) // 先输出 0 1 2
}
(1)这道题涉及到了异步、作用域、闭包:
settimeout是异步执行,10ms后往任务队列里面添加一个任务,只有主线上的全部执行完,才会执行任务队列里的任务,当主线执行完成后,i是3,所以此时再去执行任务队列里的任务时,i全部是3了。对于打印3次是:
每一次for循环的时候,settimeout都执行一次,但是里面的函数没有被执行,而是被放到了任务队列里面,等待执行,for循环了3次,就放了3次,当主线程执行完成后,才进入任务队列里面执行。
(2)当解决变量作用域:
for (let i = 0; i < 3; i++) {
setTimeout(function () {
console.log(i)// 3s 后输出 0 1 2
}, 3000)
console.log(i) // 先输出 0 1 2
}
因为for循环头部的let不仅将i绑定到for循环块中,事实上它将其重新绑定到循环体的每一次迭代中,确保上一次迭代结束的值重新被赋值。setTimeout里面的function()属于一个新的域,通过 var 定义的变量是无法传入到这个函数执行域中的,通过使用 let 来声明块变量,这时候变量就能作用于这个块,所以 function就能使用 i 这个变量了。
由于 var 命令的变量提升机制,var 命令实际只会执行一次。而 let 命令不存在变量提升,所以每次循环都会执行一次,声明一个新变量(但初始化的值不一样)。于是得出结论:
for 的每次循环都是不同的块级作用域,let 声明的变量是块级作用域的,所以也不存在重复声明的问题。let声明变量的for循环里,每个匿名函数实际上引用的都是一个新的变量。
参考链接:https://blog.csdn.net/m0_37816134/article/details/100053012
14.求以下代码的结果
(1)考察作用域,this指向
var a = 11;
function test2(a) {
this.a = a = 22;
let b = function () {
console.log(this.a)
}
// let b = () => { console.log(this.a) }
b();
}
var x = new test2();
console.log('x:', x);
结果:11, x: {a: 22}
(2)考察全等,未声明变量赋值
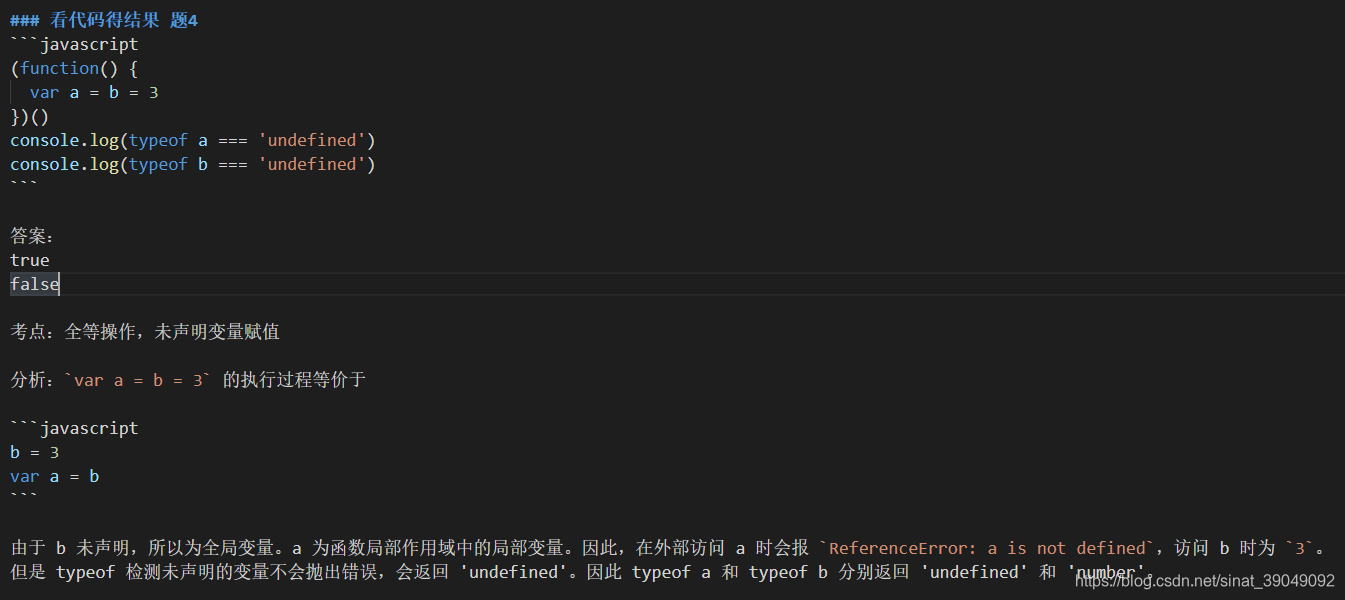
(3)考察变量声明提升和函数声明提升
1)变量提升
var scope = 'global';
function f(){
console.log(scope);
var scope = 'local';
console.log(scope);
}
由于函数内声明提升,所以上面的代码实际上是这样的
var scope = 'global';
function f(){
var scope; //变量声明提升到函数顶部
console.log(scope);
scope = 'local'; //变量初始化依然保留在原来的位置
console.log(scope); //local
}
经过这样变形之后,答案就就非常明显了。由于scope在第一个console.log(scope)语句之前就已经定义了,但是并没有赋值,因此此时scope的指是undefined.第二个console.log(scope)语句之前,scope已经完成赋值为’local’,所以输出的结果是local。
原文链接:https://blog.csdn.net/qq673318522/article/details/50810650
2)函数声明提升
var getName = function () {
console.log(2);
}
function getName() {
console.log(1);
}
getName();
我们这里对js的函数声明提升进行拆分,得到以下结果:
var getName;
function getName() {
console.log(1);
}
getName = function () {
console.log(2);
}
getName(); //2
(4)考察暂时性死区
var a = 1;
if (true) {
console.log(a)
let a = 1
}
//Uncaught ReferenceError: Cannot access 'a' before initialization
在代码块内,使用let、const命令声明变量之前,该变量都是不可用的。这在语法上,称为“暂时性死区”(temporal dead zone,简称 TDZ)
(5)考察setTimeout在for循环中的执行顺序
给出以下代码,输出的结果是什么?原因?
for(var i=0;i<5;i++) {
setTimeout(function(){
console.log(i);
},1000);
}
console.log(i)
在一秒后输出 5 个 5
原因:每次 for 循环的时候 setTimeout 都会执行,但是里面的 function 则不会执行被放入任务队列,因此放了 5 次;for 循环的 5 次执行完之后不到 1000 毫秒;1000毫秒后全部执行任务队列中的函数,所以就是输出 5 个 5。
15.给两个构造函数 A 和 B,如何实现 A 继承 B?
function A(...) {} A.prototype...
function B(...) {} B.prototype...
A.prototype = Object.create(B.prototype);
// 再在 A 的构造函数里 new B(props);
16.前端书籍
《Head First HTML 与 CSS》、《CSS 揭秘》、《CSS 世界》、《CSS 权威指南(第三版)》、《JavaScript 语言精粹》、《JavaScript 高级程序设计(第三版)》
原文链接:https://blog.csdn.net/sinat_39049092/article/details/114260739
所属网站分类: 技术文章 > 博客
作者:加油打工人
链接:http://www.qianduanheidong.com/blog/article/33512/f8f13f5a4d8db278af0f/
来源:前端黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力