

字节前端一面面经
发布于2021-05-30 07:44 阅读(737) 评论(0) 点赞(10) 收藏(2)
算法题
1. 实现函数

arguments:用在函数内部,表示传给该函数的所有的实参的集合。
虽然arguments对象并不是一个数组,但是访问单个参数的方式与访问数组元素的方式相同。
function foo(){
let sum = 0;
console.log(arguments);//伪数组或者类数组对象
//arguments[0]取到第一个实参值,arguments[arguments.length-1]取到最后一个实参值
//console.log(arguments[0],arguments[1])
//var sum = arguments[0]+arguments[1]+arguments[2]+arguments[3];
for(let i = 0; i < arguments.length; i++){
sum += arguments[i]
}
console.log(sum);;
}
foo(1,2,3,4,5,55);
function sum(){
let num = arguments[0];
if(arguments.length == 1){
return function(next){
console.log(num + next);
}
}else{
for(let i = 1; i < arguments.length; i++){
num += arguments[i];
}
console.log(num);
}
}
sum(2,3); //5
sum(2)(3); //5
2. 定时器

function myTimer(fn, a, b) {
let timer = null
let count = 0;
function delayFn() {
timer = setTimeout(function() {
fn();
count++;
delayFn();
}, a + count * b);
}
delayFn()
return function() {
clearInterval(timer);
};
}
function fn() {
console.log(fn);
}
myTimer(fn, 1000, 1000);
3. 函数节流
let lock = false;
btn.onclick(function () {
if(lock) return;
// 事件操作
lock = true;
setTimeout(function () {
lock = false;
}, 2000)
})
4. let和var区别


第一个输出0,1,2
第二个输出3,3,3 // var声明的变量会影响全局,污染其他局部变量
面试题
1. TCP UDP的区别
https://blog.csdn.net/zhang6223284/article/details/81414149
参考这篇吧!
2. 为什么不建议使用 index 作为 key 值
key 值存在的意义. 我们可以简单把它理解为每一条数据的唯一标识. 它与这条数据是关联在一起的
假如index当作key,数组中的某一个数据被删除了,那么其他数据的index就会发生变化,随着页面的重新渲染, key 值也发生了变化

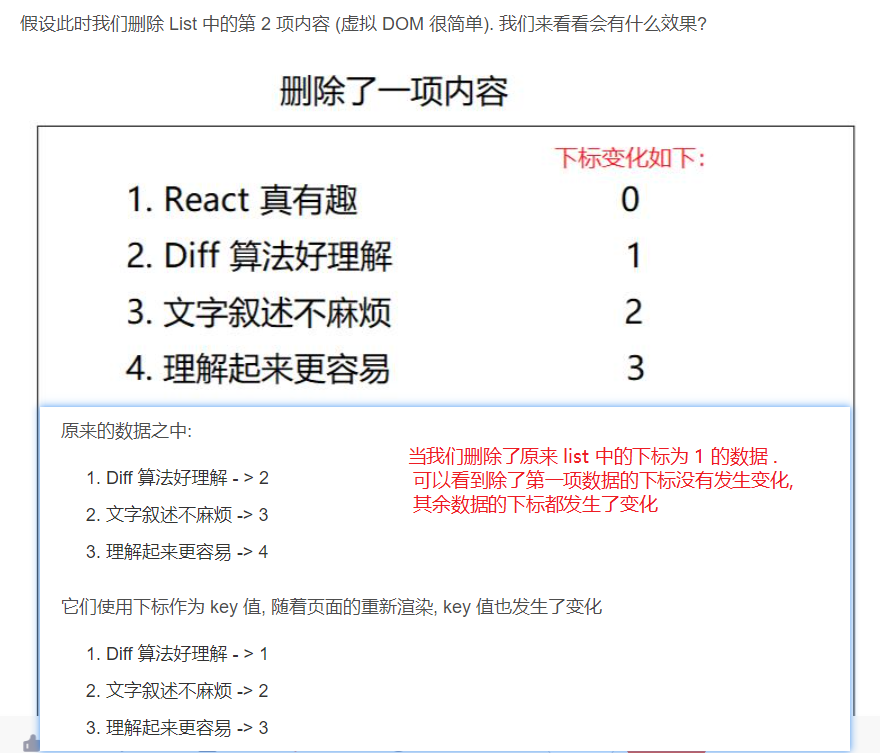
以前的数据和重新渲染后的数据随着 key 值的变化从而没法建立关联关系. 这就失去了 key 值存在的意义
开发过程中, 因为我们的数据绝大部分都是从后台获取来的. 数据库中每一条数据都会一个 id . 作为唯一标识. 而这个 id 也是我们最常使用作为 key 值来源
3. 跨域
3.1 JSONP 原理
JSONP 只能发送 GET 请求,不能POST
JSONP 用的是 script 标签,与 AJAX 提供的 XMLHttpRequest 没有任何关系

1)服务器端
在浏览器定义的fun函数里面是想要执行的操作
因AJAX没办法跨域,就只能让script,img,iframe等发送跨域请求
script标签发送请求,将客户端的函数名传递到服务器端,服务器接收到请求,就把请求到的数据(客户端想要的数据)和函数名一起作为字符串响应到客户端
重要!!!跨域问题只存在于客户端,不存在于服务器端,所以服务器是可以正常访问另外一台服务器获取数据的,但是客户端的AJAX没办法跨域,就不能正常拿到数据
下面的图片是服务器端,返回的是客户端定义的函数和想要的数据
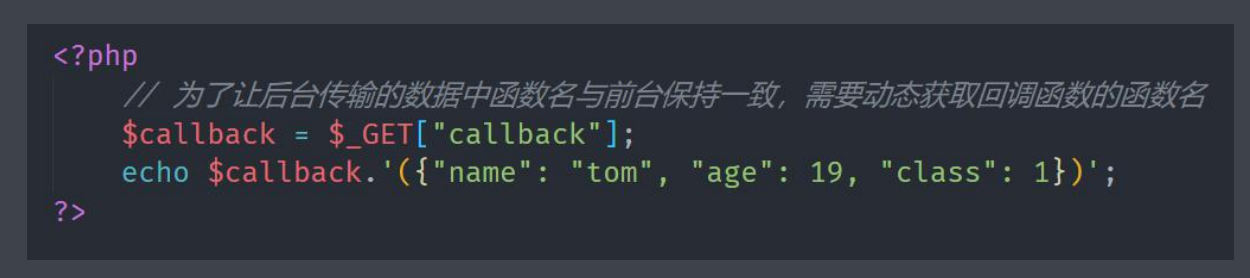
服务端响应的数据是定义在客户端的函数和相应的数据
2)客户端
客户端接收到服务器端的响应,函数fun(data)立刻执行
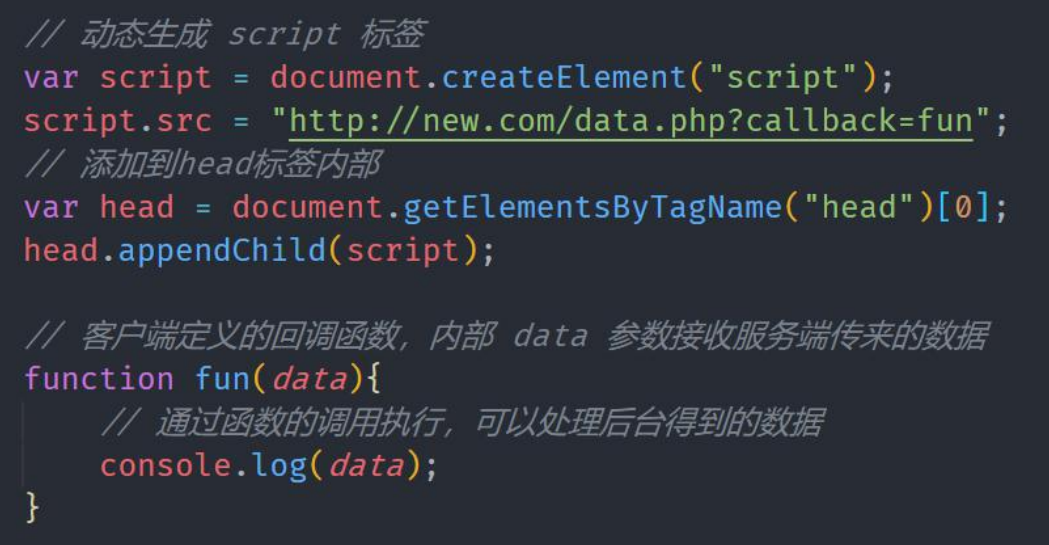
3)jQuery 中的 jsonp
JQ自动分析dataType属性,假如是jsonp那就跳过AJAX请求,发送script标签请求;假如不是,那就执行AJAX请求

$(".btn").click(function () {
// 发送跨域的 ajax 请求
$.ajax({
url: "https://www.baidu.com/sugrec?pre=1&p=3&ie=utf-8&json=1&prod=pc&from=pc_web",
type: "GET",
dataType: "jsonp",
jsonp: "cb", //这条属性可以设置回调函数的参数名称(必须与后台接口的回调函数参数名保持一致)
jsonpCallback: "abc", //jQ 自动分配的回调函数的名称进行重命名
data: {"wd": "ajax"},
success: function (data) {
console.log(data)
}
})
})
3.2 CORS 跨域
浏览器不需要任何操作,正常发送ajax请求,实现cors跨域的关键是服务器,只要服务器实现了cors接口,就可以跨域通信


3.3 Nginx反向代理跨域
服务器容器中设置跨域请求头
在 nginx.configure => server模块 => location模块 下增加
add_header: “Access-Control-Allow-Origin” "*"
add_header: “Access-Control-Allow-Method” "GET, POST, PUT, DELETE, OPTIONS"
Nginx反向代理可以设置多个可以跨域的源,但是cors跨域只能设置一个源或者所有源(不安全),Nginx反向代理在浏览器和服务器之间虽然是存在的,但是体验上是透明的,只是起到了搭桥连线的作用。反向代理的大概意思就是,在你想要请求的服务器A附近的LAN网络下找一台你可以请求的服务器B,而且这台服务器B是可以正常访问服务器A的,你就可以委托服务器B来请求服务器A
4. 浏览器存储
**cookies:**h5之前,存储主要用cookies,缺点是在请求头上带着数据,导致流量增加。大小限制4k
**localStorage:**以键值对(Key-Value)的方式存储,永久存储,永不失效,除非手动删除。IE8+支持,每个域名限制5M
**sessionStorage:**sessionStorage操作的方法与localStorage是一样的,区别在于 sessionStorage 在关闭页面后即被清空,而 localStorage 则会一直保存。很多时候数据只需要在用户浏览一组页面期间使用,关闭窗口后数据就可以丢弃了,这种情况使用sessionStorage就比较方便。注意,刷新页面sessionStorage不会清除,但是打开同域新页面访问不到
三者之间的区别:
- cookie属于DOM,sessionstorage和localstorage都属于BOM
- cookie过了时限会过期,历览器自动删除cookie;sessionstorage存储在页面会话期间可用,只要浏览器处于打开状态,包括页面重新加载和回复;localstorage浏览器关闭,重新打开数据依然存在,除非手动删除
- sessionstorage在不同的浏览器页面中是不能共享的,只能在同一个页面;localstorage和cookie在所有同源窗口中都是共享的
- cookie数据不能超过4K,因为需要在发送网络请求的时候携带cookie;seeionstorage和localstorage可以达到5M
5. 数组去重
let arr = [0,1,2,2,3,1,5];
let b = [...new Set(arr)];
6. 字符转反转
split方法切割字符串成字符串数组,reverse方法反转数组,join方法拼接成字符串
7. 对象new底层怎么实现的
比较直观的感觉,当我们new一个构造函数,得到的实例继承了构造器的构造属性(this.name这些)以及原型上的属性。
当我们new一个构造器,主要有三步:
• 创建一个空对象,将它的引用赋给 this,继承函数的原型。
• 通过 this 将属性和方法添加至这个对象
• 最后返回 this 指向的新对象,也就是实例(如果没有手动返回其他的对象)
改写上面的例子,大概就是这样:
// ES5构造函数
function Parent(name, age) {
//1.创建一个新对象,赋予this,这一步是隐性的,
// let this = {};
//2.给this指向的对象赋予构造属性
this.name = name;
this.age = age;
//3.如果没有手动返回对象,则默认返回this指向的这个对象,也是隐性的
// return this;
};
const a = new Parent('一拳超人', '24');
这应该不难理解,你应该在工作中看过类似下述代码中的操作,将this赋予一个新的变量(例如that),最后返回这个变量:
// ES5构造函数
function Parent(name, age) {
let that = this;
that.name = name;
that.age = age;
return that;
};
const a = new Parent('一拳超人', '24');
为什么要这么写呢?我在前面说this的创建与返回是隐性的,但在工作中为了让构造过程更易可见与更易维护,所以才有了上述使用that代替this,同时手动返回that的做法;这也验证了隐性的这两步确实是存在的。
但上述这个解释我觉得不够完美,它只描述了构造器属性是如何塞给实例,实际上原型上的属性是也是要给实例继承的:
• 以构造器的prototype属性为原型,创建新对象;
• 将this(也就是上一句中的新对象)和调用参数传给构造器,执行;
• 如果构造器没有手动返回对象,则返回第一步创建的对象
对象会继承构造器的原型与原型上的属性,最后它会被作为实例返回。
手动实现一个简单的new方法:
// 构造器函数
function Parent (name, age) {
this.name = name;
this.age = age;
};
Parent.prototype.sayName = function () {
console.log(this.name);
};
//自己定义的new方法
function newMethod (Parent, ...rest) {
// 1.以构造器的prototype属性为原型,创建新对象;
let child = Object.create(Parent.prototype);
// 2.将this和调用参数传给构造器执行
Parent.apply(child, rest);
// 3.返回第一步的对象
return child;
};
//创建实例,将构造函数Parent与形参作为参数传入
const child = newMethod(Parent, 'echo', 26);
child.sayName() //'echo';
//最后检验,与使用new的效果相同
child instanceof Parent//true
child.hasOwnProperty('name')//true
child.hasOwnProperty('age')//true
child.hasOwnProperty('sayName')//false
8. Object和Array的实例判断
可以用intanceof判断,typeof判断Array实例会返回Object类型
9. 选择器的优先级
! import > id选择器 > 类选择器 > 标签选择器 > 通配符
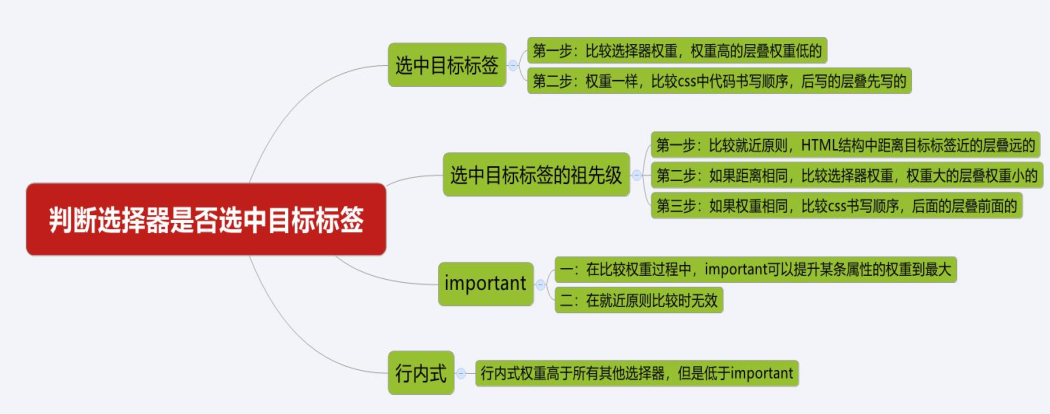
10. http和https之间的区别,1.0 1.1 2.0版本的区别
1 HTTP1.0和HTTP1.1的区别
1.1 长连接(Persistent Connection)
HTTP1.1支持长连接和请求的流水线处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启长连接keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。HTTP1.0需要使用keep-alive参数来告知服务器端要建立一个长连接。
1.2 节约带宽
HTTP1.0中存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能。HTTP1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,客户端接收到100才开始把请求body发送到服务器;如果返回401,客户端就可以不用发送请求body了节约了带宽。
1.3 HOST域
在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname),HTTP1.0没有host域。随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都支持host域,且请求消息中如果没有host域会报告一个错误(400 Bad Request)。
1.4缓存处理
在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
1.5错误通知的管理
在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
2 HTTP1.1和HTTP2.0的区别
2.1 多路复用
HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。HTTP1.1也可以多建立几个TCP连接,来支持处理更多并发的请求,但是创建TCP连接本身也是有开销的。
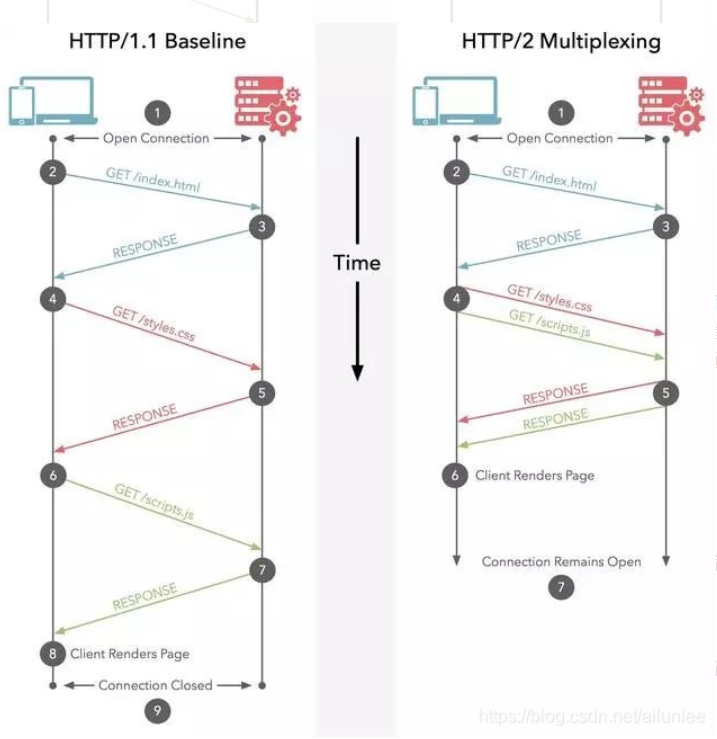
2.2 头部数据压缩
在HTTP1.1中,HTTP请求和响应都是由状态行、请求/响应头部、消息主体三部分组成。一般而言,消息主体都会经过gzip压缩,或者本身传输的就是压缩过后的二进制文件,但状态行和头部却没有经过任何压缩,直接以纯文本传输。随着Web功能越来越复杂,每个页面产生的请求数也越来越多,导致消耗在头部的流量越来越多,尤其是每次都要传输UserAgent、Cookie这类不会频繁变动的内容,完全是一种浪费。
HTTP1.1不支持header数据的压缩,HTTP2.0使用HPACK算法对header的数据进行压缩,这样数据体积小了,在网络上传输就会更快。
2.3 服务器推送
服务端推送是一种在客户端请求之前发送数据的机制。网页使用了许多资源:HTML、样式表、脚本、图片等等。在HTTP1.1中这些资源每一个都必须明确地请求。这是一个很慢的过程。浏览器从获取HTML开始,然后在它解析和评估页面的时候,增量地获取更多的资源。因为服务器必须等待浏览器做每一个请求,网络经常是空闲的和未充分使用的。
为了改善延迟,HTTP2.0引入了server push,它允许服务端推送资源给浏览器,在浏览器明确地请求之前,免得客户端再次创建连接发送请求到服务器端获取。这样客户端可以直接从本地加载这些资源,不用再通过网络。
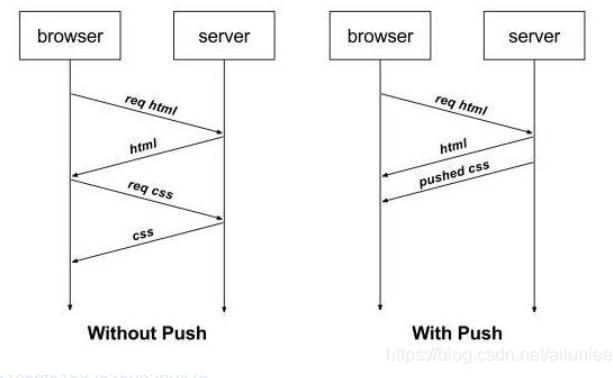
11. 强制缓存和协商缓存
- 强制缓存是我们在第一次请求资源时在 http 响应头设置一个过期时间,在时效内都将直接从浏览器进行获取,常见的 http 响应头字段如 Cache-Control 和 Expires
- 协商缓存是我们通过 http 响应头字段 etag 或者 Last-Modified 等判断服务器上资源是否修改,如果修改则从服务器重新获取,如果未修改则 304 指向浏览器缓存中进行获取
12. GET 和 POST 请求的区别
- GET 参数通过 url 传递,POST 放在 body 中。(http 协议规定,url 在请求头中,所以大小限制很小)
- GET 请求在 url 中传递的参数是有长度限制的,而 POST 没有。原因见上↑↑↑
- GET 在浏览器回退时是无害的,而 POST 会再次提交请求
- GET 请求会被浏览器主动 cache,而 POST 不会,除非手动设置
- GET 比 POST 更不安全,因为参数直接暴露在 url 中,所以不能用来传递敏感信息
- 对参数的数据类型,GET 只接受 ASCII字符,而 POST 没有限制
- GET 请求只能进行 url(x-www-form-urlencoded)编码,而 POST 支持多种编码方式
改则 304 指向浏览器缓存中进行获取
12. GET 和 POST 请求的区别
- GET 参数通过 url 传递,POST 放在 body 中。(http 协议规定,url 在请求头中,所以大小限制很小)
- GET 请求在 url 中传递的参数是有长度限制的,而 POST 没有。原因见上↑↑↑
- GET 在浏览器回退时是无害的,而 POST 会再次提交请求
- GET 请求会被浏览器主动 cache,而 POST 不会,除非手动设置
- GET 比 POST 更不安全,因为参数直接暴露在 url 中,所以不能用来传递敏感信息
- 对参数的数据类型,GET 只接受 ASCII字符,而 POST 没有限制
- GET 请求只能进行 url(x-www-form-urlencoded)编码,而 POST 支持多种编码方式
- GET 产生一个 TCP 数据包;POST 产生两个 TCP 数据包。对于 GET 方式的请求,浏览器会把 http 的 header 和 data 一并发送出去,服务器响应200(返回数据)。而对于 POST,浏览器先发送 header,服务器响应100 continue,浏览器再发送 data,服务器响应200 ok(返回数据)
所属网站分类: 技术文章 > 博客
作者:Hggh
链接:http://www.qianduanheidong.com/blog/article/115821/9047171aff4943b52e43/
来源:前端黑洞网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)
---无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事,而不是让内心的烦躁、焦虑,坏掉你本来就不多的热情和定力